

Model Description: Others
Learning
The system learns using unsupervised learning by reinforcement: the strongest of the memory is based on the number of facts that is received (tendency/frequency) and the different sources.
When the system receives a positive assertion about a concept and a characteristic is considered that the mentioned concept has that characteristic. As more trust or times that association is received more real can be considered that assertion. The same assumption for the negative facts.
Assuming the same intensity, in case the system receives a positive input; after receives the same input but with negative, then if you ask about that fact, the answer will be Yes or No, in other words which entry is the good?; The system assumes that both are valid, but as the tendency of that fact now is zero, the answer will be "Unknown" the same answer as if the system it never been received those inputs.
Also it learns by regulating the source:
Humans have the ability to assign trustworthy (through the emotion) to the received information depending of the source; we can hear a thousand times on TV or movies that in a few years we will live on Mars, but only one time in a book written by NASA, explaining the impossibility of this in the short term, for we decline to don't believe that is possible to live on Mars.
The system does not have the ability to assign more weight to one source than to another (no emotion management), but it allows the user to impose their trustworthy to the assertions learned earned so far.
In the case of this system, the steps are:
As the reinforcement is based in the size of the frequency (number of tendency) and the variety of the source.
In the case of having the fact "cat is a mammal" (introduced 4 times for 3 different imputers) and also "cat is a robot" (1 input, 1 source);
For the system a cat is a mammal and a robot, but it could be deduce that "cat is more mammal than robot".
Unlike the human brain, the system does not suffer interferences, distractions, amnesia or other brain diseases.
So every assertion will be stored in the system.
Forgetting system
Purge some knowledge when is poorly referenced or does not have enough sources to be considered as real fact.
Currently the system does not have any mechanism to forbid knowledge or "clean the memory"
But this it could be for example remove every assertion which frequency is not higher than certain a threshold (example, if every word has been mentioned at least 100 times, but there is a noun only mentioned once, it's probably this noun has been inserted into the system through an lexical error) or it does not have enough variety of sources (as for example, never it has been confirmed).
Tendency and Source
The tendency is the mechanism which allow to the model to set if a fact or assertion is true or false
cat is nice → nice has a positive relation with cat
cat is not big → big has a negative relation with cat
This value implies the directly in the answer of questions about this assertions.
This indicator is not binary (true/false) is a number that also indicates the intensity of the relation, as bigger is the number as more reliable is the assertion. If a same fact receives the same number of positives inputs than negatives ones, the tendency will be neutralized (= zero) than it would be interpret as the relation never has been inputted (the known about this fact is unknown).
As only with the number of times a fact is inputted is not enough to know how reliable is this fact, there is associated another indicator, the source that implies as much variety of inputter provided this assertion more trust will be.
Both tendency and source are associated with every entry of each list of the frames (parents, features,...).
Also if the tendency is positive there also will create an entry in the correspondent list of the affected set, creating an inverse relation.
is cat nice? Yes ←→ What is nice? cat
is cat big? No ←→ What is big? None
Remind, from the application you can adjusts the parameters that affects directly the tendency: trust, source
Learning by question confirmation
Question confirmation is the mechanism that provides the interface for correct manually [supervised learning] the current knowledge, normally provided via text or automated extractions from the web [unsupervised learning]. Don't forget the users can train or even lie the system through this mechanism.
Taking the following scenario:
1. Into the memory the fact cats have legs was mentioned twice (tendency = 2).
2. The @mode confirmation is activated.
3. The answer for the question does cats have legs? will be Yes
4. Then the application will ask to the user if this response is rigth.
5. Based on the user answer,
5a. (Yes) the fact will be reinforced → increasing the number(frequency) of the tendency
5b. (or No) or correct → the tendency of that relation will be changed.
This mechanism could be replaced by providing the sentence cats has not legs to the system once and again (or once by setting an higher enough trust) in the case of detract mode,
or setting a more appropriated strategy as invert or force.
Due to several elements that can be involved in the answer, and the complexity of check each of them, this mechanism is not applied to the group questions (what ... ?).
|
For the system, learning is equal than populate the memory structures, task that is reduce to process the Internal Language extracted from the language processing. |
 |
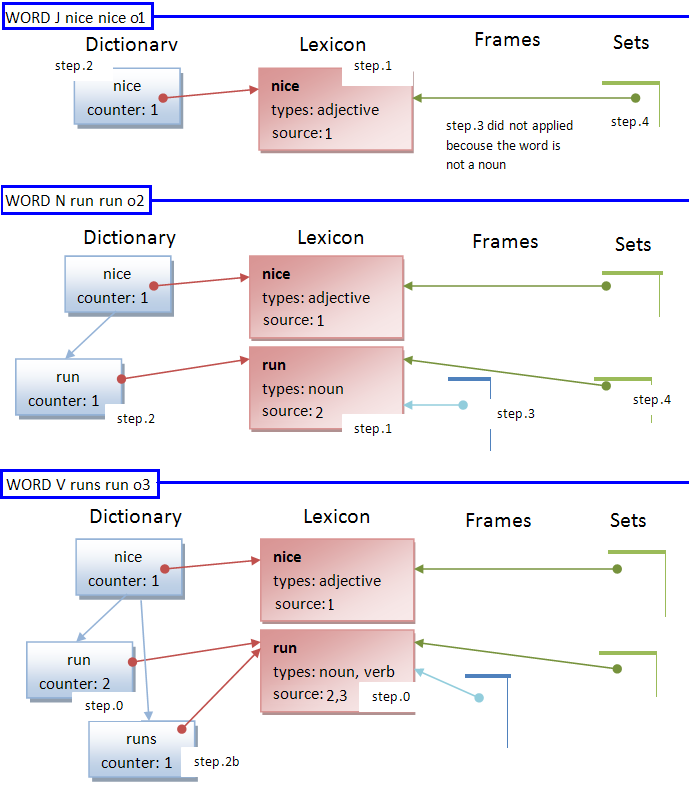
WORD type term lemma source
0. if the word already exists in the dictionary then increments their counters and adds the source in the lexicon
else
it runs the memory flow of insert new concepts:
1. insert the lemma into the lexicon getting the reference of the concept
2. insert the term into the dictionary associating the term with the lemma trough the lexicon reference
2b. if the term and lemma are different, then also insert the lemma into the dictionary
(now the concept can be accessed by many words as the system knows always referring to the same concept)
3. if the type is noun also creates a new entry in the frame storage (pointing to the lexicon reference)
4. it creates a new set entry for this concept
Let's see a graphical example that how works this flow.
Assuming the memory is empty. The system receives the following internal language codes: source1="word J nice nice", source2="word N run run", source3="word V runs run"
subject ILCODE object trend
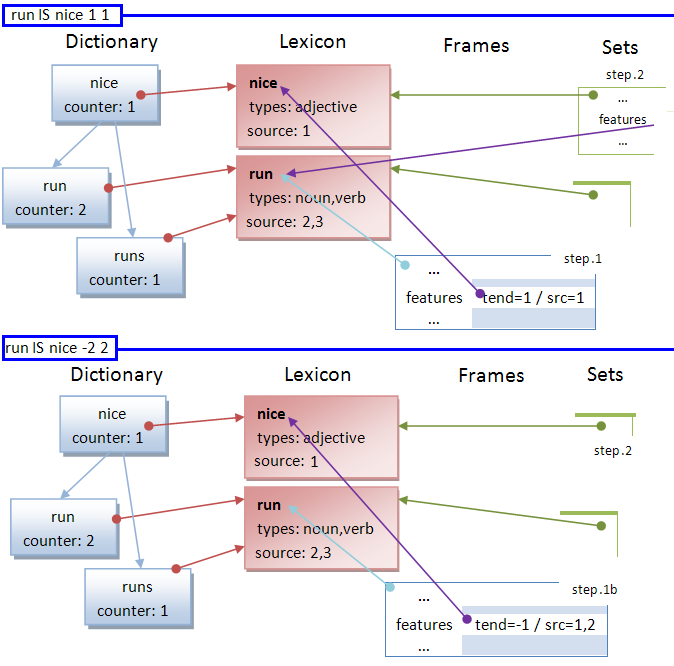
The process of adding associations or relations to the memory knowledge is very simple:
1. insert a new element (object) into the correspondent list (ilcode) of the subject frame
| IL code | destination list |
|---|---|
| ISA | parent |
| IS | feature |
| HAVE | attribute |
| CAN | skill |
| CANBE | affected action |
| ADJNOUN | ambiguous adjectival nouns |
| OFCALUSE | ambiguous of clauses |
| ISAIS | both in parent and feature |
1b. if the element already exists then updates the existent tendency with the trend
2. Based in the tendency of the relation, adds or removes the element from their correspondent set list.
Remind the lists of the sets are populated only with elements that it has positive tendency.
The elements stores in every list of the frames and sets are really lexicon references, this implies that before call a relation internal language code,
it's mandatory the subject and the object exist into the memory; It has previously processed their correspondent internal language word code to every subject and object.
Continuing with the prior example scenario. The system receives the following inputs:
- trust=1 / source=1 / sentence= the run was nice → run IS nice 1*1 1
- trust=2 / source=2 / sentence= runs aren't nice → run IS nice -1*2 2
At this phase no mechanisms of emotional processing won't be implemented.
So, every sentence will be processed as a descriptive: intonation, mood, rhythm, context and other quibbling emotional messages will be discarded.
Also, no discrimination or preferences linked to emotion will be applied when making the decision of store or not knowledge into the long term memory.
Therefore, every assertion extracted from sentence analysis will be stored in the memory.
The system manages the following states of consciousness:
- awakeness → external input are accepted, external output is produced.
- pass out → application failure.
- sleeping → memory maintenance tasks.
(not implemented yet )
In sleep state, if a sensory input exceeds his threshold, the brain initiates an emergency mechanism to wake it up.
E.g. a very loud sound or someone touches with enough rude [the system would emulate this behavior using an @ order].
Unless is not "awake" (is not running properly), the system will pay attention to every input and order received.
Future: In case two or more inputs arrive for different channels at the same time, the priority orders are:
1. Touched (keyboard)
2. Listened (microphone)
3. Viewed (cameras)
Note: in a human brain, there are also priorities in the sensorial inputs, but sensory memory is limited both space and time, therefore the inputs can be loose, it also can be loosed by don't pay enough attention.
The attention is managed by the hippocampus, but in this model no attention mechanism is implemented.
The system will pay attention to every received input and also it decides to store always in the long term memory every extracted information.