

Although the Stanford CoreNLP can deal with several sentences, the system will split the text into simple sentences.
Also will adapt the text for obtain results as the "semantic analyzer" expects.
Take in mind the CoreNLP is quite sensible to syntactic errors.
Actions applied to the input text:
Stanford NLP Core deals correctly with contractions. But for the system is better to avoid them,
for not introduced them into the dictionary (which word is 'm ?)
"it" has an impersonal usage (it rains)
or as rhetorical device
to avoid repeat again the subject in the sentence ("Look that dog!, it looks ill", instead of "Look that dog!, that dog looks ill")
In neither case, "it" can be interpreted as a concept to associate relations.
"the cat scratched my head", it doesn't matter if is my head or your head, for the system the important is that "heads can be scratched".
Therefore in a semantic context "my money is our gain" is the same than "money is gain".
E.g., the sentence "All t4r sales are non-refundable! ; Don't close the door (neither the window)".
Sentence1= All sales are not refundable
Sentence2= Do not close the door, neither the window

In essence, this subprocess consist on getting the results obtained from the Standford NLP core, and convert the branches of their constituent tree into internal language, that represents the grammatical relations which populates the memory structures (learning).
|
Basically, the idea is apply the following rules to every sentence provided in the system:
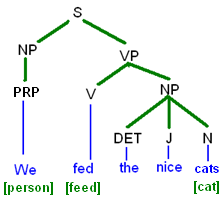
From the part of speech and the constituent tree obtained from Stanford NLP core (S
(NP (PRP We))
(VP (VBD fed)
(NP (DT the) (JJ nice) (NN cat)))
)
|
|
Remind constituent trees are tagged with the Penn Treebank
(NP (DT the) (JJ nice) (NN cat)) → cat
(NP (DT the) (JJ nice) (NN cat)) → "cat IS nice"
(NP (DT the) (VBG jumping) (NN kangaroo))) → "kangaroo CAN jump"
(NP (DT the) (NN animal) (NN man)))
this case ambiguous, "animal" is a parent or a feature of "man"?
it can't be resolved with only this information, therefore It's stored in the frame memory as an special case ("man ADJNOUN animal" )
or directly with the agrupation "can + be": the pen could was thrown through the window "pen CANBE throw"
When the sentences are negative (has the negative conjunction NOT), the relations are the same except for his tendency (in the memory are stored in a format that clarifies that this is a negative relation when is asked)
But there is an exception if the object has modifiers, in this scenario the negative notation affects the attribute not the relation:
For example taking the sentence "a stool doesn't have large backrest"
the fact of stools doesn't have large backrest does not implies stools can't have backrest
→ "stool HAVE backrest +1 / stool%backrest IS large -1 "
cats can't fly → "cat CAN fly -1"
cats didn't eat the mouse
that currently does not do the action, does not mean the subject can never do it
so only if the specified verb is can then the action verb is accepted as negative skill
Therefore in this special case → "cat CAN eat" (positive)
Same scenario as above, only when the verb can is specified the action verb will be accepted as negative affected action
"that dog did not barked at the cat" → "cat CANBE bark" (positive)
"the dog can not bark at the cat" →"cat CANBE bark -1"
The verb 'can' is a modal, and the negative proposition ('not') affects the action verb:
"a cat can't be a dog" →"cat ISA dog -1"
In case more than one action verb is identified, the last one is considered the link verb, and the others, subject relations.
For example: dogs and cats had been looking and running in the terrace
→ [SUBJECT: dog, cat / VERBS: look, run / OBJECTS: terrace]
"dog CAN look" / "cat CAN look"
"dog CAN run" / "cat CAN run"
"terrace CANBE run" / E,g. "Cat is a small mammal and a good pet"
small and good will be assign to cat, instead of small to mammal and good to pet respectively
"cats has retractile claws"
retractile is referring to claws of cat, nor to a cat neither to claws in general
"cat is not a big animal" → cat ISA animal / cat IS big -1
"cat has not big claws" → cat HAVE claw / cat%claw IS big -1 (the symbol % means "reference to the attribute of")
The cat is nice and good but never eats good food.
Processed by point 3
Processed by point 2.
a car with big wheels has stopped in the pavement →"car have wheel" + "wheel of car are big"
"a man without big hands" → the man have hands but NOT big hands.
"a man without hands" → assuming that in this case the man is an instance, therefore this man don't have hands, but men in general have hands.
"the table of good wood is expensive" Table is made of wood (feature) or the table has wood (attribute)
When you include other knowledge you can conclude that this sentence is referring to a table made of wood. But not when you only dispose of grammatical information.
As this scenarios is ambiguous are stored in the frame as an special case → table OFCALUSE wood
This kind of sentences will be processed separately in parts, the main sentence plus the WH phrase replacing the relative clause for each identified subject
"cats and dogs, that are not robots, are mammals"→"cats and dogs are mammals" + "cats are not robots" + "dogs are not robots"
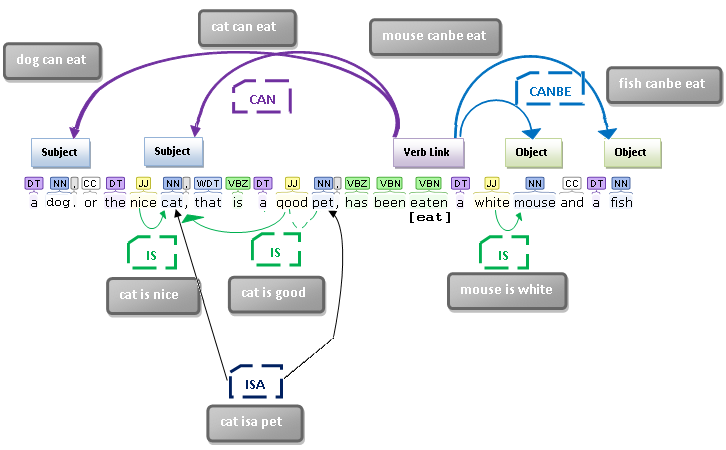
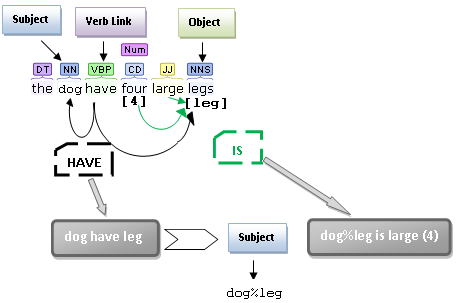
Some graphical examples of grammatical analyzing and their relation with their correspondent internal language code
By design, the parser has some limitations:
On multiple relative clauses, the content of the clause is assume for all the identified subjects
E.g.: "cats, dogs and birds, that are pets, are nice
The parser assumes that PET is a relation for CAT, DOG and BIRD
but
E.g.: "the phone, that is a device, and the printer, that is a unit, have power plug"
phone ISA device / printer ISA unit (and also phone ISA device) / + phone and printer HAVE power plug
Of Clauses can process more than one concept, this could be confused with multiple subject sentence
"spoons made of iron or wood are used for stirring"
spoon HAVE iron / spoon HAVE wood / spoon%iron CAN stir / spoon%wood CAN stir
but
"teams of basket, companies and workers pay taxes"
the identified subjects are team%basket, team%company and team%worker instead of team%basket, company and worker
Sentences such as "cars have parts composed of some elements" or "keyboards have keys that contains letters"
are not processed due to its constituent tree complexity it should be processed as separated sentences
E.g.: "parts of cars has elements" or "keys of keyboards has letters"
This phase receives the language relations (in internal language format) extracted from the previous phase;
therefore it processes every internal language code to insert them into the memory structures.
Obviously storing something that can't be retrieved does not make any sense.
to ask if a concept has a characteristic, it only allow affirmative questions, but obviously it can answer with negative response. E.g. "Is cat small?" or "Have dog tongue?".
to know which concepts has some characteristic. E.g. "What is nice?" or "What animals can fly?".
"terrace CANBE look" (as 'look' is not the link verb, objects are not affected by them)
Lastly, there are some exceptions when in the NPs contains modifiers, that affects the rules described in the point 2
In both cases exceptions, if a negative conjunction appears then the negation affects to the modifier not to the object
Take in mind, the parts of the sentence far of the identified objects will be processed applying the point 2.

Question Answering

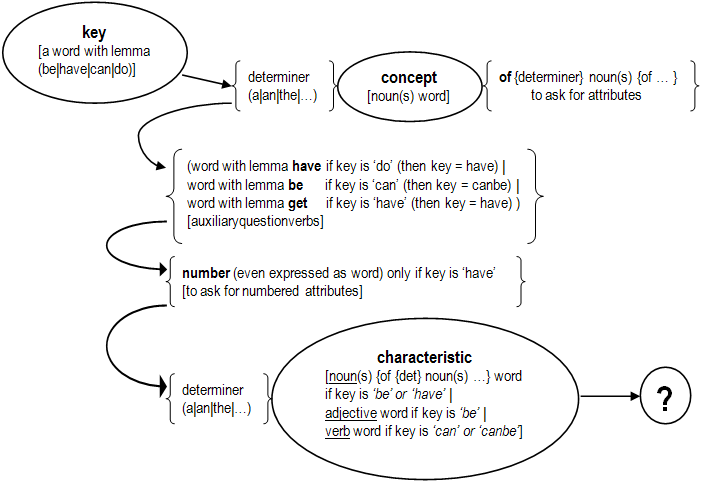
The system allows the access to the concepts and their characteristics, using stereotyped questions as:
The symbol "?" is quite important when is input in the command line, is the key for be interpreted as question (information retrieval) instead of declarative sentence (learning).
Those stereotype questions it can be used with normal names and determinants for a most natural usage.
Which does not prevent to create unnatural questions, as "do cat has an legs?"; but for the system this is valid question (= have cat leg?)
Affirmative questions accepted graph:
() | separated list with the valid options
{} means not mandatory
Note: numbers could be write in word format, but it must be write in a unique "-" separated word, as for example "a-hundred-fifty-six".
The maximum accepted number is less than a million (999.999).
Examples:
* when multiple nouns are referenced the indefinite article is important to split correctly the concepts
if no indefinite article is indicated, then only the last noun is considered the characteristic
is leg an upper limb? → concept = leg / characteristic = upper limb
is leg upper limb? → concept = leg upper / characteristic = limb
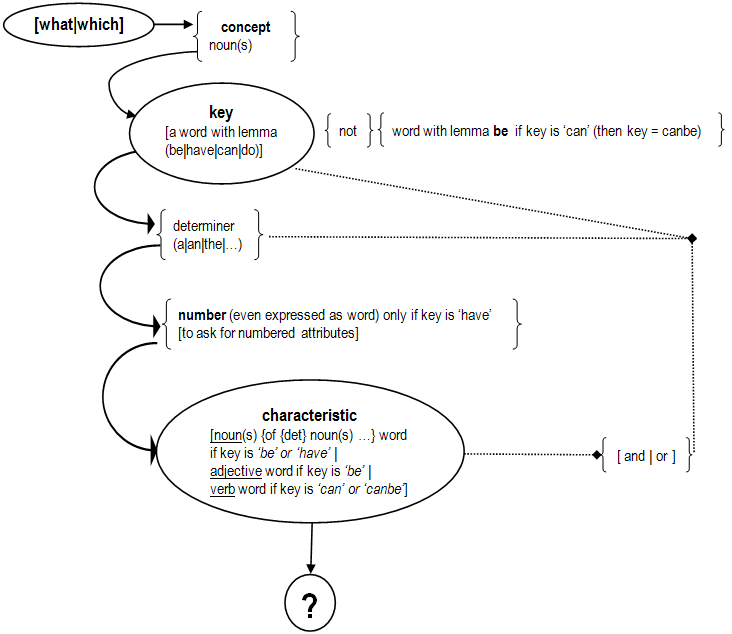
Group questions accepted graph:
() | separated list with the valid options
{} means not mandatory
Notes:
Therefore "what is big and large?" is equal to "what is big and is large?"
Examples:
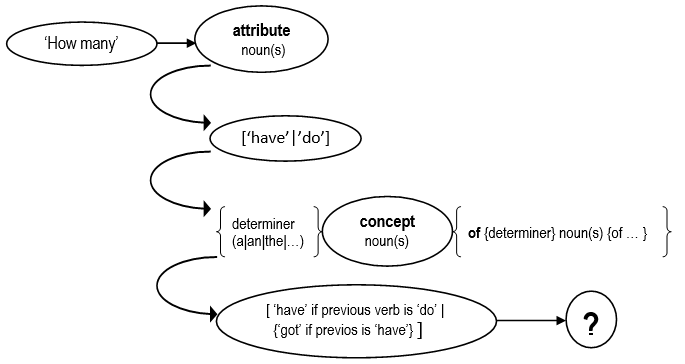
Numbered attribute questions accepted graph:
() | separated list with the valid options
{} means not mandatory
Notes:
- "None" → in case the object has not relation with the attribute.
- "Any" → if the object has the attribute, but no numbers has been mentioned over the relation.
- "comma separated list of numbers" → the object has the relation with associated numbers, then return the list (ascending sort, no duplicates)
See here how is searched in memory.
Examples:
Interactions question accepted graph:
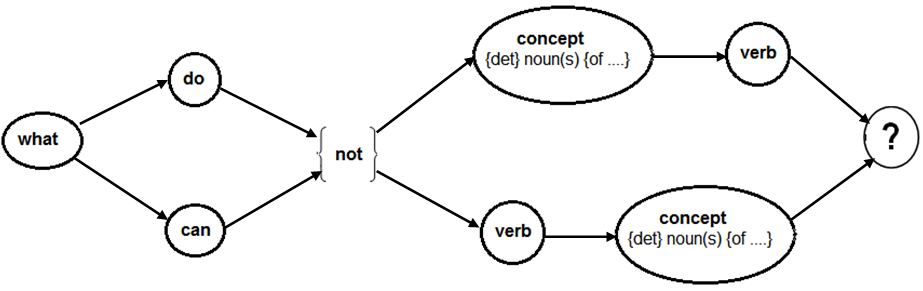
() | separated list with the valid options
{} means not mandatory
Notes:
- "None" → in case no interaction has been found or fit the conditions of the search.
- "comma separated list with the concepts than has the asked interaction.
Remind the negative particle affects only the interaction, not the relation, so the concept have to have a positive skill relation with the verb and the interaction having the negative tendency.
See here how is searched in memory.
Examples:
Interactions affirmative question accepted graph:

() | separated list with the valid options
{} means not mandatory
" " means a word wich lemma is the word between the quotes
Notes:
1 - the concept has the action verb in their skill list with positive tendency.
2 - the skill has the indicated receiver in their interaction list with positive tendency.
3 - the receiver has the indicated action verb in their affected action list with positive tendency.
If any of these conditions failed then the answer will be "No".
As this kind of question has the same properties than the affirmative question, so the confirmation mechanism is also activated acting in the same defined way.
Negative particles are not accepted in the graph, becouse if the relation is negative then the answer will be negative.
Due to the attribute inheritance search, Of-clauses are not allowd as it's not necessary to ask.
See here how is searched in memory.
Examples:
1. The model is focused in simple declarative sentences, not in speeches, discussions or any other (large) text context dependent.
2. Stanford NLP core is quite sensible to language errors; therefore syntax errors must be avoided as much as possible.
3. As the verbal time doesn't have importance in the declarative memory, it's only necessary to get the infinite verb: Jumped or jumping → jump
4. Auxiliary or modal verbs doesn't have semantic value, therefore are discarded. Except "to be" and "to have" due to are descriptive ones.
"The cat should have eaten": as "should" is modal and "have" is an auxiliary in this sentence, then the verb that acts as main verb is "eaten" (cat can eat)
5. At this phase doesn't interpret specific or proper "objects".
Then personal pronouns and proper nouns will be translated into the concept that represents.
New York, Barcelona or Japan → location
We, John → person
ONU, FBI → organization
That translations are known as NER (named entity relation) and is provided by Stanford NLP core
"Jimmy jumps"; Jimmy is a person → person can jump
6. The same sentence can have multiple constituent trees (that are valid different interpretations), but unfortunately how the sentence is formed (or how the Stanford NLP Core provides the tree) would obtain ones or others results.
In this sentence the system don't detect the "cats has 4 legs" because "four" is outside of the noun phrase of the concept:
The four legged cats: (ROOT (NP (NP (DT The) (CD four)) (NP (JJ legged) (NNS cats))))
Instead, these sentences will catch it correctly
the four legs of cats: (NP (NP (DT the) (CD four) (NNS legs)) (PP (IN of) (NP (NNS cats)))))
cats has 4 legs: (S (NP (NNS cats)) (VP (VBZ has) (NP (CD 4) (NNS legs))))
7. Questions must be formulated in affirmative way.
Anyway you can ask can receive negative answers. Instead of asking for "Are cat not big?" → "are cat big?" No
For groups (object guessing), negative questions are allowed.
Check also the list of the considerations and limitations of the model and application.