
Deployment of the application and first steps
Aseryla_X.zip*1 must be decompressed*2 and it has the following structure:
- Aseryla.exe: the main server application.
- ASERYLA_xxxx.cmd/.sh: files to start, stop ... the Aseryla service.
- Aseryla_GUI.exe (/GUIw): the graphical interface.
- cmd_interface.exe: the command line interface.
- NLP_xxxx.cmd/.sh: files to control the NLP kit service.*3
- /data: the stored memory file and other auxiliary files
- /database: data, needed libraries, ...
*1 X = L(inux) or W(indows)
*2 The distributable is configured for running in "/home/{user}/aseryla" ("C:\Users\Public\aseryla" in Windows)
*3 NLPcore service is not included in the package, it must be downloaded
and placed inside the "NLPstanford" folder (where Aseryla_X.zip was decompressed).
For an easy first contact, follow the graphical interface.
To run the system:
1. Init the NLP kit service, for Aseryla could analyze the input sentences.
o Run "{aseryla}/NLPstart.cmd" (or .sh for linux OS as for example: nohup bash NLPstart.sh > /dev/null 2>&1 &)
Remind that it requires at least a version 1.7 of Java.
- The initialization of this process spends from seconds to some minutes, depending of the machine is running.
If you have some knowledge of Java application, you can verify the requirements
and adjust the memory allocation when the Java application is called (-Xmx800m) in the "NLPstart" command file.
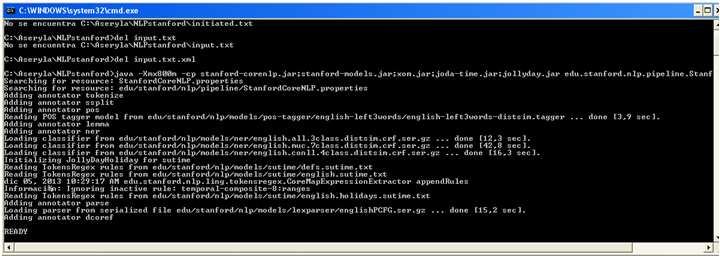
-When the service finishes its initializations is ready to receive sentences.
You can test it, using the command file "NLPtest".

This application in origin works providing a file (or files in a folder) with the text to analyze and then produces an output file with the results in a file with the same name plus ".xml".
As you can see in the example, the command file "NLPtest" provides a file named "input.txt" (with a dummy text inside) and the application produces a file "input.txt.xml" with the results.
You obtain the same results if you set the content of the input file into their online demo web and then you save manually the results into a file.
To avoid the long spend time in the initializations for each sentence to analyze, the main provided source code as been modified for not exit after an input is processed and all the file communication has been replaced by network socket communication, simplifying the workflow and improving the performance (such as removing all the "unused" information tags).
You can find the modified source code in "StanfordCoreNLP.java", only a few part of the remarked as "ADAPTATIONS FOR ASERYLA" has been modified/added, the rest of the source remains untouched.
| Cycle of life of the (adapted) Stanford NLP Java service |
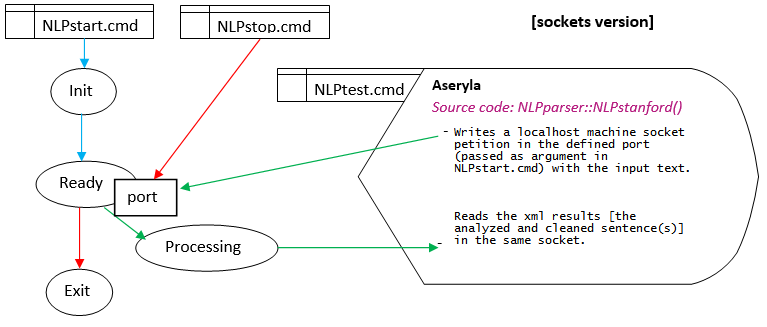 |
Description about the kit and an example of output results
|
The default socket port number set as parameter in the "NLPstart.cmd" is the 9902, always for the same machine is running (localhost).
To send and receive messages from the server, is provided a little Java application (NLPclient.class), that is used by "NLPtest.cmd" to send a sentence and show the results, or even to shutdown the service (NLPstop.cmd, sends a #exit# message).
2. Run the command line console.
o Run {aseryla}/aseryla.exe {optional parameters}
The aseryla application has been transformed into a service, allowing to operate multiple interfaces
(such as command line, web, graphical) and even more than one user at once.
Run {aseryla}/aseryla.exe [working_port] [NLP_port]
- working_port: where the service will listen and write the socket communication (9901 by default).
Every external interface that would like use the service has to write and read
(this petitions) in the local machine to this defined port.
- NLP_port: where the Stanford Core NLP service is listening the orders (9902 by default, check the "NLPstart.cmd" arguments)
or simply execute "ASERYLA_start.cmd".
Note that is important to close the service using the right way (executing "ASERYLA_stop.cmd", not clicking in the X),
because the service does some important memory task when a shutdown order is received.
Then you can run the command line interface ("cmd_interface.exe" [working_port])
9901 is the default working port, the same port where the aseryla service is processing the petitions.
Note, every time the application is started, it will process the batch file "init.txt"
(in case exists in the {aseryla} folder),
quite useful for setting the custom initializations.
There are available some alternatives web interface and graphical interface.
With this action you will run the system and the command line interface, in the call as optional order you can indicate a file with commands to set the environment,
as the log file, what show or not, and other commands (valid commands are show typing @help). Including sentences to analyze or even questions.
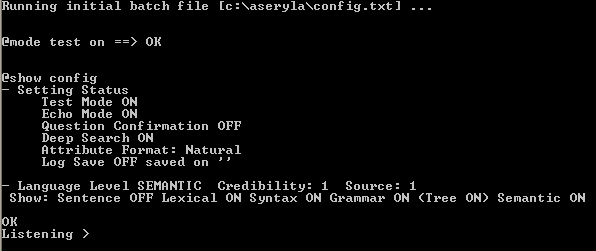
Calling Aseryla with an initial batch as parameter is the same as running aseryla.exe and then the type @load batch batch_file.
This console initializes the system (loads the memory files with all the learned knowledge previously) and starts an interactive command line system which you can ask for:
- Process sentences: (learning) language analysis plus memory insertion
Inputs, batch files and text files as processed as declarative sentence
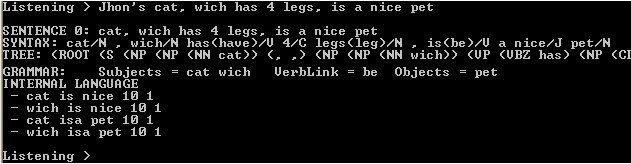
- questions: (?) information retrieval
Input or batch file that finishes with the symbol ? (Note: In text files is interpreted as sentence separator.)
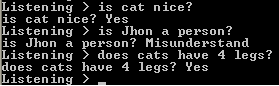
- System orders: (@) useful to change the settings or apply some actions over the system
Input, or batch file line, that starts with the symbol @ are interpreted as orders)

| Interactive flux of the interface (console input workflow) |
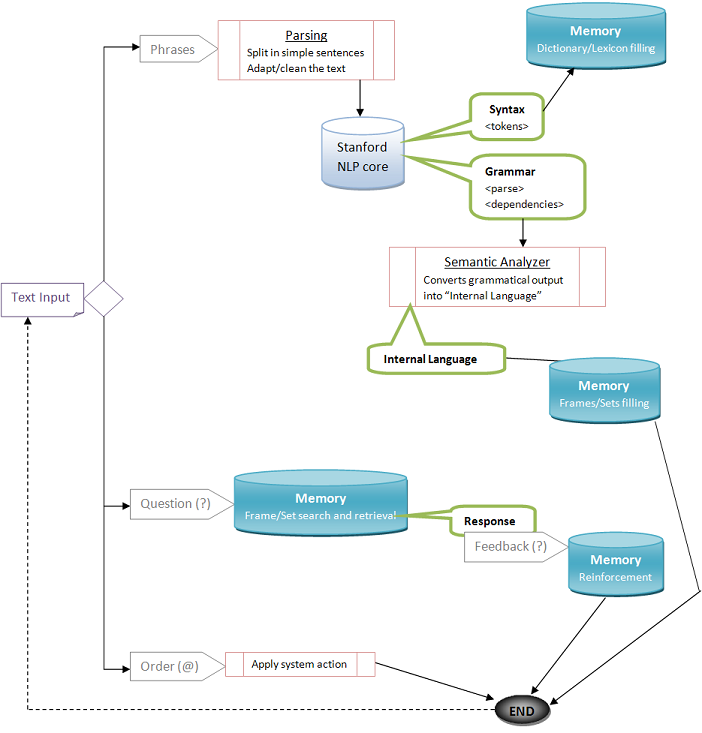 |
|
|
System backup and recovery
When the application/service is closed the content of the memory is saved into the "memory.ase" file in the "{aseryla}/data" folder.
It's highly recommended to apply a manual backup of the memory file from time to time. And also saving the content in internal language format.
In case the system falls by any detectable application failure, the application also tries to save the memory in order of not losing any knowledge.
The system autoload itself the minimal words to run the system, so if you want to empty the memory, you only need to rename or remove the
{aseryla}/data/memory.txt file.
On the other hand, every time a sentence fails when processing the application stores it into the table "errors" of the database {aseryla}/database/aseryla.db. This allows that in case of an application failure, you can know which sentence produced the trouble
(especially useful when text files are processed)
Finally, as the latest option, into the database is stored enough information to recover the system, but taking in mind, that there is only the information provided to the system via sentences (no ilcs, no manual confirmations).
Memory management
The management of the memory can't be controled by the user. No more test mode option, no more manual saving.
The service will manage automatically when to save their content, or not, based in performance reasons,
by default each 100 processed sentences, but for example when files are loaded the content is saved only when the process finishes.
The system uses a database (SQLlite / stored in {aseryla}/database/aseryla.db / check schema.sql) for:
- Stores all the processed sentences to be queried (E.g.: by the GUI)
- Extra data storage for the memory content. As the internal language codes of every processed sentence.
- Store auxiliary data.
- Saves the current input before is processed. This allow, in case the server falls down, knowing what input produced the failure.
- Safety measure when a large number of sentences are processed, e.g. load file or book.
Allowing an automated mechanism for "try again" sentences which failed during the process.
"{aseryla}/data/error_nlp_kit.txt" file has been replaced by the "failed" & "errors" database tables.
E.g.: processing a file, it obtains the following results:
sentence1 → OK
sentence2 → NLP not initiated
sentence3 → NLP parser failed
sentence4 → OK
sentence5 → NLP parser failed
Therefore, sentences 1, and 4 are stored in the "sentences" table (obviously also in the memory) and sentences 2, 3 and 4 in the "failed" table.
Then, the system assumes that is a temporary problem with the NLP kit, and it process again those not OK sentences.
Sentences that failed in this second step, are not processed again, for maintenance reasons are stored in the "errors" table.
Unless are failed because the NLP kit is not running, that scenario is not a system failure.
Memory Clean Up
When the system is shutdown, and just before the content of the memory is saved.
By explicitely petition: the system applies a clean, purge and tidy up process to the memory content.
That consists in, delete those frames that don't have any relation (empty concepts) and also for every characteristic list of every frame:
- Removes every element with neutral tendency → less elements in the list implies shorter searches
- Sets pointers to the first negative relation in the list → spends less time expanding and exploring the nodes in deep searches
- Sort the elements by higher frequency / more diversified source, setting the positives ones first
→
reducing the time of the searches (the most used words has higher probabilities to be searched again)
Also the adjectives and verbs that has no mentions in the relations.
The concepts that only has NER and/or specializations relations.
E.g.: "eiffel_tower ISA location" + "eiffel_tower ISA tower" (if it has other relations then is not filtered)
And those interactions which skill reference is not mentioned with positive tendency in its affected actions list.
E.g.: "ox CAN jump ocean*1&1 1 1" + "ocean CANBE jump / -1 1"
In average this process could spend 1 sec to process 2,500 ilcs, and It reduces about 30% the size of the memory file.
Be concerned about the memory file is replaced, so maybe you have to make a backup before proceed.
This process may be executed twice to clear some empty attribute frames that can't be removed the first time this process is executed.
You may find the following python script useful for removing some undesired relations.
*1 Check the SYSTEM FAILURE ACTUATION in the main.cpp file of the source code
*2 Check database.h/.cpp, and srvInterface / functions: tFile() and tReprocess()