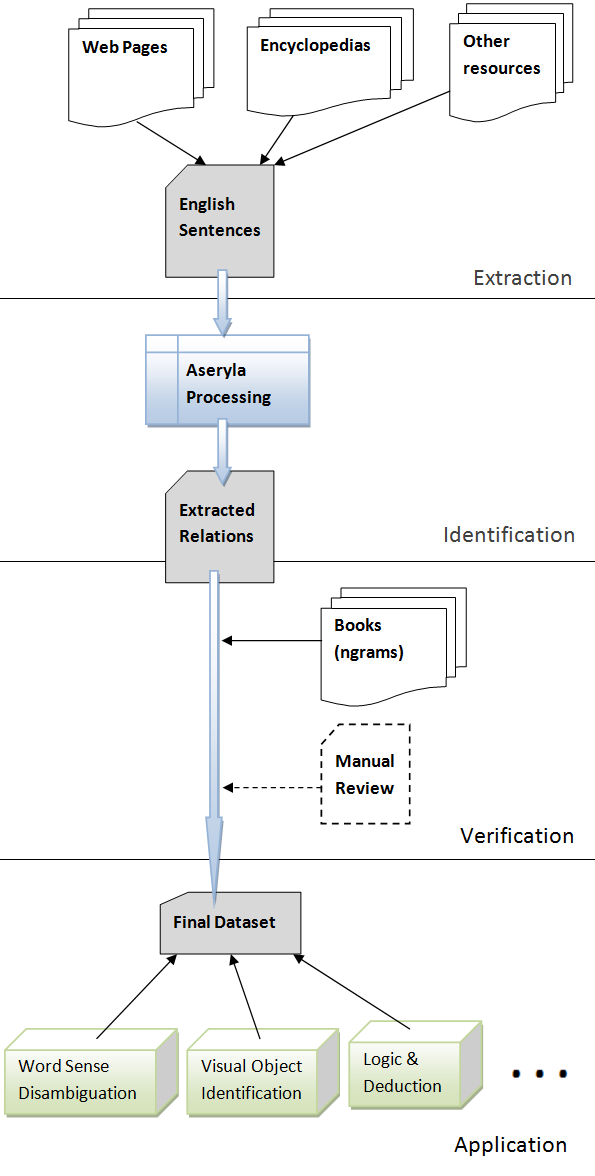

Extracting general information from the web, it's a hard work, almost impossible of complete.
So We will focus the efforts trying to achieve what the system can learn about one concrete concept ("motorcycle" in the explained example).
The aim is checking the quality of the data and relations that you can obtain using the proposed system.
Using a slightly modified version of the script WebExtractor.py;
you can crawl the web pages that are related with the concept "motorcycle", selecting only those sentences that are mentioned it.
In fact, I got 1086 web pages (filtering by web domain, to avoid using the same text again and again), where it was extracted about 1200 sentences with the word "motorcycle" (or their variants "Motorcycle", "motorcycles", ...).
The text was processed; extracted their relations (removing the duplicate ones by page using the following script) and finally cleaned.
So the system has identified 26065 relations; about 5000 has a tendency higher than one, that means the same relation appears in different pages.
Is that enough for having a good knowledge, let's see:
- 1 mention (tendency = 1)
person isa humber_motorcycle → this seems false
person isa rider_motorcycle → this could be true
- relations with multiple mention (tendency higher than one)
person isa scooter_commuter → this seems false
person isa motorcycle_enthusiast → but this is true
So you can deduce that having the same relation mentioned in different points of the same source (web pages in this example) it's not enough.
Then it's needed to find alternative paths. What if we mix with other sources? such as encyclopedias, that is a reliable source:
When you process the entry motorcycle that offer the Wikipedia:
The system identifies 234 sentences, where you extract 446 relations (60 of them has a tendency higher than one).
When you mix both files (after change their correspondent sources), you get 26515 relations, where only 131 of them it appears in both files (source = 96, that it's the mix of 32 = webpages + 64 = encyclopedias). E.g.:
- person can close motorcycle_shop*1&1 1 96
- motorcycle is electric / 30 96
- motorcycle is heavy / 3 96
Therefore crossing different origins (source), sounds more promising than rely in the number of times mentioned (tendency).
Nevertheless the number of relations that you can extract from a encyclopedia are very limited compared with the relations identified in web pages.
In the example, from the 349 features identified in the web pages, only 11 has been identified in the encyclopedia.
As adding new sources seems a good idea, to my mind comes ... BOOKS.
But collecting and processing lots of books are a task harder than crawling the web.
Google did it! And fortunately they opened the data.
"DO NOT uncork the champagne but it may be worth cracking open a beer"
The amount of data is huge (several Terabytes of text), processing that text could spend several years (similar time than processing the WWW).
So you can get a bi-gram ("an n-gram is a contiguous sequence of n items from a given sequence of text or speech") assuming that if two words appear together several times (Google filtered those relations that do not have at least 40 mentions) in different books, than those must be related.
Why two? why not 3 or 4 or ...
The response is that if you play a little bit with their web page, you find out that with 2 words works pretty well (e.g.: red sparrow) but can't find trigrams such as "sparrow is red".
Fortunately, the bigrams files (there are plus than 700 files) could be considerably reduced if you remove the time references (http://storage.googleapis.com/books/ngrams/books/datasetsv2.html), discarding the non English words and the non semantic words (determiners, adverbs, etc.), lemmatizing the content, grouping the concepts ...
From Terabytes of text files to a 244 MB text file!
The final file obtained from the bigrams has the following format:
Each line is a whitespace word list, where the first element is the first word of the bigram and the rest are the related words that appear in the bigrams.
The entire file has been lemmatized (for checking the relations), the words only contains values from 'a' to 'z', nor uppercase, nor dashes, nor numbers, ...
E.g: when in the bigrams files you process the following entries: "nice cat" / "nice dog" / "nice farm"; the line in the final file will be "nice cat dog farm"
The scripts used for parsing the bigrams files are here
Going back to the point of getting all the knowledge about "motorcycle".
We obtained almost 27k relations from webpages and the Wikipedia. On the other hand we have million bigrams with relations extracted from the books.
How many relations can be found in the bigrams? The results obtained was than 75% of the relations matched!
You can execute the following script (106 MB compressed) for doing that task.
This script get a memory file in ilc format with a name "memory_ilcs.txt" and using the bigrams file (ngramed.txt), it creates an output file (ngram_verified.txt) with the list of relations with source 8 (the expected source for books relations) when the concepts of the relation matched with the bigrams file. This output file can be directly loaded in the system Tc command or using the GUI.
E.g:
Assuming the content of the memory_ilcs.txt file is:
WORD N cat cat
WORD J nice nice
cat is nice / 1 1
fox is nice / 1 1
fox is good / 1 1
The ngramed.txt file contains the following entries:
nice cat dog car tree
fox small good animal
Then, after the execution of the script, the content of the ngram_verified.txt results file will be:
cat is nice / 8 1
fox is good / 8 1
This image summarizes the entire process.
The following tool has been used for lemmatize the bigrams file, but it could be used for any text file:
| Ubuntu | Windows | source code |
|---|---|---|
 |
 |
 |
Usage:
- Go to the folder (it's assumed that has write permissions) where the executable "file_lemmater.exe" is.
- Copy any text file and then rename it to "in.txt".
- Then execute the .exe and you will obtain an output text file named "out.txt" with the results.
Basically the application applies the following rules:
- All the characters are translated to lowercase respecting their original position inside the file.
- When a sequence of letters (a-z or A-Z) is found then their lemma is searched in the key-value file "lm.dat"; if found then is replaced. Otherwise it assumes the lemma of that word is the same word but in lowercase.
- Only the semantic words (nouns, verbs, adjectives) are lemmatized (because the "lm.dat" file only contains this kind of words).
- If a word contain a dash (E.g.: warm-blooded) is processed as 2 different words.
- The "lm.dat" contains more than 195000 entries. With only words that their lemma is different (e.g.: cats cat; Cat cat is not necessary).
So if you want to add any new lemmatization, You only need a new line in this file with the format: word(whitespace)lemma.
E.g:
Assuming the content of the in.txt file is:
the cats are warm-blooded.
The spendend1 is a ship (or ships) with a pretty paint hulls
KO: is the acronym for Know Out
After the execution, the content of the out.txt file will be:
the cat be warm-blood.
the spendend1 be a ship (or ship) with a pretty paint hull
ko: be the acronym for know out