
It's a must have a data structure that allows store the concepts, features, attributes and skills extracted from the language analysis, as well as a container that list the words and syntactic information from the processed words.
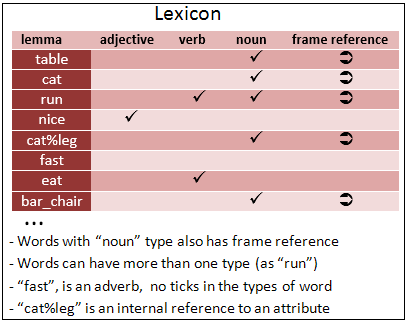
A lexicon is essentially a catalogue of a given language words.
The system will save every semantic word. Semantic words are nouns (concepts and attributes), verbs (skills) and adjectives (features);
The rest of types of words has syntactic and grammatical meaningful as adverbs, modal verbs, conjunctions, interjections or punctuation.
This structure is a list of every lemma existent in the dictionary with the types of word that is.
As a word can be of various types, (e.g. animal is a noun or an adjective depending of his position inside a sentence) the structure allow store more than one type.
In case the word has noun type, the system will create a new frame and it will save his reference to facilitate his posterior search.
Valid set of words extracted from the sentences with the corresponding reference to the lexicon.
In the dictionary only will be stored words with semantic meaning (nouns, verbs and adjectives) and also adverbs for others purposes.
The system considers that a word doesn't exists if it doesn't appear in the dictionary.
The system handles only general concepts, but thanks to the dictionary, the system is capable to link every existent word with their concept.
Therefore when you want to refer a concept you can refer it with every word that mentions it.
E.g. if you would like to ask for a "table" you can ask mentioning "Table", "Tables" ... not only to the concept "table" (take in mind, people sometimes do not know the lemma of a word).
In fact the dictionary is not necessary for the purpose of this project, but help a lot of to interact with it; it's not the same ask for does cats four legs? that do cat 4 leg?.
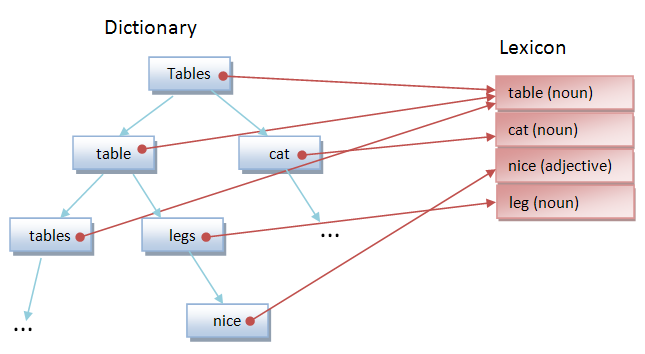
This structure will be a Tree as searches are faster than in a list.
The nodes of the tree, contains the word, a lexicon reference to their correspondent lemma, and also stores the number of times this word has been referenced and his source;
with the aim of maintenance, stats, memory purge, or even technical optimizations (to enhance the searches, usually is a good technique set the most used words first).
Based on the idea of frame
described by Marvin Minsky
and developed by Roger Schank.

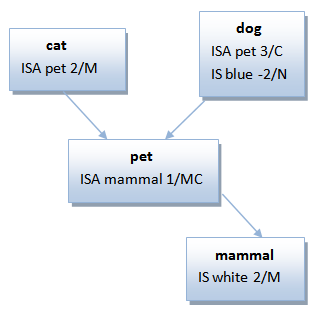
It has chosen the following a data structure for represent the general concepts, their characteristics and relations:
Concept lemma of common noun.
Every noun identified in each analyzed sentence will have frame.
As the important is the concept not the word which describes, every word that represents the same concept will be treat as the same.
Words: Cats, cat, CAT, cats → concept: cat (his lemma)
o Parents: inheritance relation.
It's a list of lexicon references of nouns with their correspondent tendency and source.
This implies, the characteristics of the parent will be taken as their own for the concept
With this list the system can categorize the concepts and also mark hierarchies
E.g. cats are animals → animal is parent of cat
Assuming animal is alive then the system can decide that also cat is alive
In this list are inserted the processed internal language with ISA code.
o Features: characteristics that describes the concept.
It's a list of lexicon references of adjectives with their correspondent tendency and source.
E.g. cats are nice → nice is a descriptive feature of cat
In this list are inserted the processed internal language with IS code.
o Attributes: properties or components which defines the concept.
It's a list of lexicon references of nouns with their correspondent tendency and source.
Attributes also has the characteristic of be enumerated, then there will be also a list of quantities associated to every attribute.
E.g.: cats has 4 legs → leg is a part of cat / "leg of cat" → 4
In this list are inserted the processed internal language with HAVE code.
o Skills: skills that concepts possess.
It's a list (of action verbs, no modal, no auxiliary) of the abilities that the concept can do.
E.g. cats runs→ cat can run
And even the relation with the concept that suffer the action (interactions)
E.g. the cat jump that fence and the stone → cat can jump fence*1&1/stone*1&1
In this list are inserted the processed internal language with CAN code.
o Affected Actions: actions that can be applied to the concept.
Actions that can affect the concept.
It's a list of action verbs, nor modals, nor auxiliary verbs.
E.g.: I jumped the cat → cat can be jump
In this list are inserted the processed internal language with CANBE code.
Note: due to the language relation processing in this list can't exists negative relations.
Notes:
- Each item of every list in the frame, it's a lexicon reference with tendency and source
- Although adverbs doesn't have semantic value, has the function of change or qualify the meaning of the word that references as adjectives or verbs.
For future porpoises adverbs will be saved along the feature or skill which references.
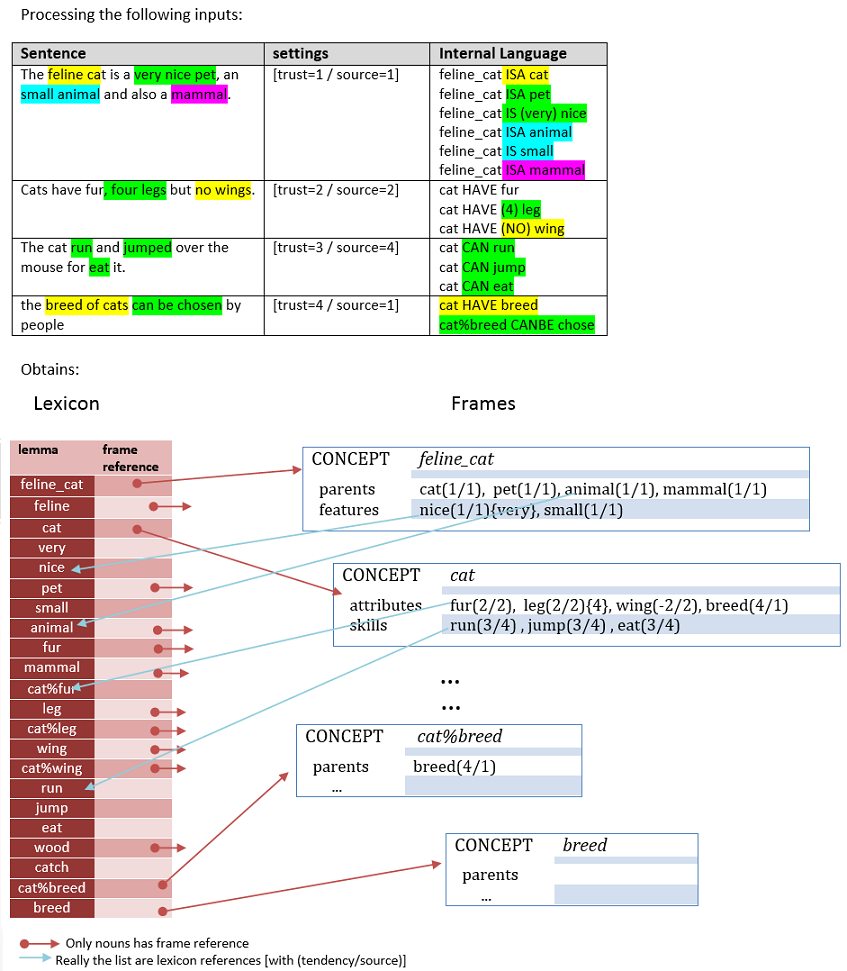
Each "noun" type defined lexicon entry, it will have a frame associated.
Weight
To each frame it has been associated a "weight"; that is a number calculated from the relations the frame has. This number determines how important this frame inside the total memory is. It's a useful measure to determine the validity of their content or for disambiguate the sense of a concept.
The idea is to giving more importance to frames with a big number of relations and different sources, than ones with a fewer relations but big tendency.
E.g. Given the following frames:
A = parents: parent1(tendency=1, different sources=2), parent2(tendency=1, different sources=2)
B = parents: parent1(tendency=4, source=1)
→ then better frame A than frame B
Also given relevance to the dispersion of the relations through the characteristics.
E.g. Given the following frames:
A = parents: parent1, parent2, parent3 / features: (none) / attributes: (none) / ...
B = parents: parent1 / features: feature1 / attributes: attribute1 / ...
→ then better Frame B than frame A
The applied formula is:
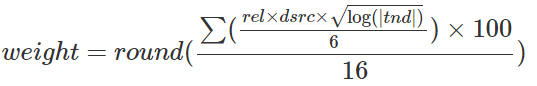
Created using HostMath - A online LaTeX formula editor and math equation editor
When, for each characteristic list and the interactions:
There is a final adjust of the formula to obtain a value 1 for frames with only one relation with tendency = 1 and a unique origin.
Examples:
Frame A (the most basic scenario, only 1 relation with tendency = 1 and unique source)
pars: a/1/1 → 1 * 1 * (1+sqrt(log(1)) = 1 * 1 * (1 + 0) = 1
feats: (none) → 0
attrs: (none) → 0
skills: (none) → 0
inters: (none) → 0
affs: (none) → 0
==> 1/6 + 0/6 + 0/6 + 0/6 + 0/6 + 0/6 = 0.166666666 → round(0.166666666 * 100 / 16) = 1
Frame B
pars: a/1/1, b/-2/2, c/10/3 note: The sign of the trend is omitted
feats: d/3/1
attrs:(none)
skills: e/4/4, f/2/2
inters: {f*1*8,g*-1*8}, {} note: interactions are counted as independent relations
affs: (none)
==> (3*2*(1+1.055))/6 + note: [origin 1 + origin 2 + origin 3=1+2 = 2 different origins]
(1*1*(1+0.69))/6 +
0/6 +
(2 * 2 * (1 + 0.88))/6 +
(2 * 1 * (1 + 0.54))/6 + note: [origin 8 + origin 8 = 1 different origin] / sqrt(log(abs(1) + abs(-1))) = 0.54
0/6
==> (2,055 + 0,28166 + 0 + 1,2533 + 0,51333 + 0) * 100 / 16 ==> round(25,64583333) = 26
This is interpreted as the second frame is 26 times "stronger" than the first one.
Basically it's a structure used by facilitate the searches of the concepts when a group question is made.
Every element will have a list of lexicon references referring to each characteristic: parent, feature, attribute, skill or affected action.
An element is added to the correspondent list when in a frame any characteristic sets his tendency greater than zero, and it's removed otherwise.
There is also the correspondent lists for the negative relations, which have the inverse behavior as describe above.
This kind of lists provide a considerable performance in searches when is necessary to explore the memory searching wich concepts does not have some characteristics, especially in object guessing.
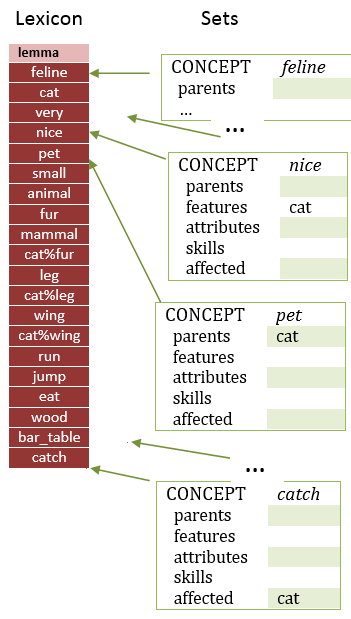
Every entry in the lexicon has the correspondent entry in the sets (being the same position in both lists).
In fact, the sets structure could be joined to the lexicon structure (it would be a single structure), but it was decided to split them for the clarification of the conceptualization.
Check the content of the memory or retrieve knowledge is made by answering the questions (also indirectly by @order show term).
For the system answering questions is the same as check if the element("characteristic") is in the correspondent list ("key") of the "concept" (Frame or Set, depending of the type of the question "affirmative" or "group"). The answer will be directly related with the value of the tendency of that element.
For the affirmative questions (searches are applied in the frame list), returns:
For group questions (searches will be run throughout the sets)
Remind the system returns Misunderstand if there is any grammar problem when the question is formulated.
Through affirmative questions that provides a key (in which list: parent, features, . . .) of the concept (initial frame to search) and the characteristic (element to search in the list and return the answer depending of his tendency). Depending of the key, the characteristic will be searched in one or other type of list:
| key | characteristic type | list to search |
|---|---|---|
| ISA | noun | parent |
| IS | adjective | feature |
| (verb BE) | noun & adjective | Ambiguous ISAIS |
| HAVE | noun | attribute |
| CAN | verb | skill |
| CANBE | verb | affected actions |
Taking the following graphical schema of an example of memory content:
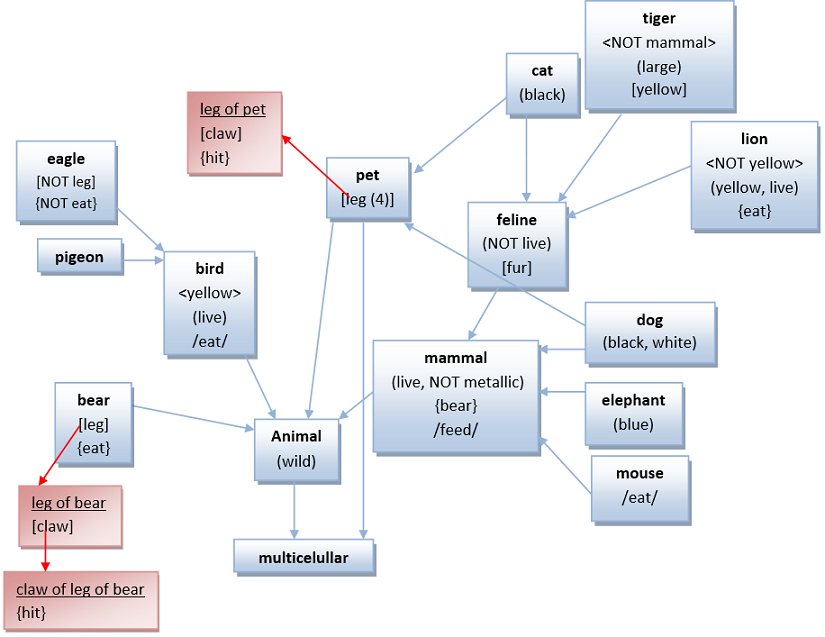
Every rectangle represents a frame
the concept is highlighted in bold
<> means a parent relation (show with the blue arrows)
() features
[] attributes (boxes in red represents the related frame)
{} skills
// affected actions
NOT implies negative tendency in the association
Note: yellow is noun and adjective, and bear is a noun and also a verb.
Let's see some simple examples that will help to clarify how the system does the searches:
- "is(key=be) dog(concept) black(characteristic)?" As the frame dog has black with positive tendency in its features (key is IS) list, then the answer is Yes.
- The question "is mouse live?" will be Unknown as it does not exist live in the list of features of the mouse frame.
- And finally "is tiger mammal?" will be answered as No.
- Take in mind that when you asked using the verb "BE" (keys ISA and IS) for a word that is noun and adjective, then there is no way to determinate if is asking for a parent or for a feature
[in the example, in the frame lion, yellow is working as adjective(features list) and as noun(parent list)]
In this scenario, the system uses the ambiguous ISAIS strategy, that consist in retrieve the response of ask by parent and by feature and then deduce the answer:
- With this memory scenario, if you ask the question "is lion yellow?" the answer will be Unknown.
[Yellow in the parent list it has negative tendency (No) + Yellow in the feature list it has positive tendency (Yes)]
- Attribute Properties(boxes in red in the figure) are also frames and the systems deal with them in the same way as regular frames.
can legs of cats hit? Yes (due to hit has positive tendency in the skill list (key = can) of the frame cat%leg
- In case of asking by an attribute using a number (Numbered Attributes), as for example "does pets have 4 legs?"
it will return Yes if the characteristic leg exist as attribute (key =have) of the frame pet and the indicated number is in the attribute numbered list of that characteristic. Answers No otherwise.
Note: If you show the term "bore" note that is interesting how the model mixed the facts learned from "born (action/verb) " and "bear (animal/noun)". Check "test.cpp" in the source code.
Take also in mind the self identity scenario.
DEEP SEARCH
Searches also could be done in a deep mode (order @mode deepsearch), that means using the inheritance property, in other words assuming the characteristics of their parents (and also grandparents) as own. This means that if the element is not found in the frame, the element will be also searched in the frames referenced in his parent list.
Considerations:
- Search first in depth through the parents of the initial node (concept)
Example: can cat born?
o born is not into cat.
o get their parents: pet and feline.
o get the checks the first that is pet; as not exists expand their parents: animal and multicellular.
o checks and expands the next that is animal, after will check multicellular, after feline, and finally the characteristic is found in their parent mammal.
- Do not analyze nor expand nodes have already processed.
For example, from pet you can reach multicellular directly or through animal; multicellular would be check only once time.
- There aren't limits in the depth.
A characteristic could be searched for the entire memory if the concepts are related by parent association.
For example the characteristics of multicellular can be inherited by lion that implies 4 degrees of kinship.
- If the question is about a skill (key = can) it will also search that characteristic in their attributes.
For example, "can pet hit?" In their skill list hit does not exist, but it has leg as attribute, and this has hit in their skill list, therefore Yes (the system consider that "pets can hit").
Some examples of deep searches:
by parent:
by feature:
by attribute:
Unlike regular deep searches of characteristic, the numbered attribute deep searches, return 'Yes' if any of his parents it has the attribute with the correspondent number, although any of his parent has the attribute but not with the searched number.
For example: does a cat have four legs?
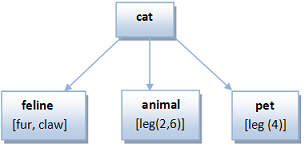
as cat does not have the attribute leg, then explore his first parent feline that neither has leg in their attribute list, then continue with animal that it has legs but 4 is not in its numbered list, finally after explore pet it found the attribute leg with the 4 within his numbered list, therefore answer 'Yes'.
In case of pet does not exist as parent of cat (also if nor animal nor feline), the answer will be 'No'.
by skill:
by affected actions:
Through group questions you can explore the same "knowledge space" but in a reverse way, moving around the sets.
As the lists of the sets are populated only with elements with positive tendency, the answer of a group questions is reduced to return the correspondent list.
If the deep search is active then also add the concepts referenced in their parent lists and so on; with not limit but not adding duplicated elements.
In case the question provides a concept (is optional) the elements of the results will be removed (filter) if they don't have the concept as parent.
For example (using the same data and knowledge as is shown above in the example figure):
by parent:
In case of deep search then the result is: feline, cat, lion, dog, elephant, mouse. [Warning: tiger is not included because has mammal with negative tendency]
by feature:
In case of deep search: bird, (+ eagle + pigeon), mammal (+ mouse + elephant + dog) [as feline has negative tendency over live therefore their "sons" are discarded]
by attribute:
by skill:
[it can hit "claws of legs of bears" and "legs of pets" by characteristic inheritance → bear and pet can hit + dog and cat that are pets]
Warning: depending of the value of @mode attrformat, the results of group questions could differ in format when attributes are referenced.
| attrformat | answer | deep search |
|---|---|---|
| None | pet%leg, bear% leg% claw | pet%leg, pet, dog, cat, bear% leg% claw , bear%leg, bear |
| Natural | leg of pet, claw of leg of bear | leg of pet, pet, dog, cat, claw of leg of bear, leg of bear |
| Main | pet, bear | pet, dog, cat, bear [duplicates are discarded] |
by affected actions:
OBJECT GUESSING
After modify the question group graph to allow multiple conditions, the system allow made more complex searches.
Therefore the memory can be queried to discover which concepts fulfils some conditions.
This mechanism could be very useful in disambiguation tasks.
Exact search
@mode deepsearch on
@mode guessing OFF
what is feline or pet or bird and have legs? dog, cat
Concepts has to fulfill every condition to be returned as results in the answer.
when an or logical operator, append the results of both sets (removing the repeated ones)
and operator, applies a set intersection operation (leaving only those elements which are present on both lists)
[1 OR 2 → cat, tiger, lion, dog] [OR 3 → cat, tiger, lion, dog, eagle, pigeon] AND 4 → cat and dog are the unique concepts on the example dataset which fulfill every condition
Approximation search
@mode deepsearch on
@mode guessing ON
what animal is wild and have legs and is live or white and can hit and not eat and is a pet?
dog(87), cat(62), bear(50), pet(50), mammal(37), bird(37), eagle(37), pigeon(37), elephant(37), mouse(37), lion(37), feline(25)
Every concept returned in the answer has associated a fulfilment percentage
| 1 - parent animal | ||||||||||||
| 2 - feature wild | 3 - attribute leg | 4 - feature live | 5 - feature white | 6 - skill hit | 7 - negative skill eat | 8 - parent pet | ||||||
| percentage |
The percentage is (cf / nc) * 100 (removing decimals)
- cf is the number of conditions fulfilled for the concept
- nc in the total number of conditions the question has
E.g. for "dog": 7/8 = 0.875; * 100 = 87.5; = 87% success rate, or the probability that this concept is the searched one
In this case, there is no difference between logical operators
- Which pet is black AND white? dog(100), cat(66)
- Which pet is black OR white? dog(100), cat(66)
The results can be managed using the guessing threshold and max results orders.
The results obtained through approximation search, when the value of the threshold is 100, are the same than the obtained using exact search.
But the exact search is a pretty fastest method, due to not always is necessary to apply a memory search for every condition.
NUMBERED ATTRIBUTES QUESTIONS
Using the kind of question described here, you can ask about the values (numbers) of attributes of any concept.
Using the example dataset schema showed above:
The alternative is check their frame content. Or asking for every number using the numbered affirmative questions.
As for example: does a cat have four legs? Yes; have cats got 5 legs? No; have...
The search is made by applying the following algorithm:
Search in each attribute and the attributes of their attributes
Every relation counts, the numbers found in all of them, are mixed and answered as unique response.
Do not explore in the attributes of nodes which have a no neutral relation
if is not found in the previous steps
and only if the deep search is active
Let's see some examples using the following example data set:
scenario 1
| - how many legs | does the person have? | 2,4 | → positive tendency relation with values in the numbered attribute |
| - how many limb | does the person have? | Any | → positive tendency relation, but no values declared |
| - how many arm | does the person have? | 1 | → explicit value |
| - how many wings | does the person have? | None | → negative tendency relation |
| - how many hands | does the person have? | None | → no relation |
scenario 2
| - how many claws | does the person have? | 10 | → from the attribute "limb". The "claws of wings" are not taken in count due to the attribute "wing" has negative tendency,
neither the " claws of mammal " because the relation has been found in their attributes, so the parents are not explored |
| - how many fingers | does the person have? | 1-5 | → 1 from the attribute "arm" (when the search it has more than one value, empty numbered list takes the value of one),
2,3,4 from "claw of limb ", and 5 from the attribute "leg" (also 3, but duplicate elements are removed from the answer) |
| - how many toes | does the person have? | Any | → from the attribute "claw of limb of person" |
scenario 3
| - how many eyes | does the person have? | 6 | → from the parent "mammal" (as the relation has been found, the parents and sub-attributes of this concept are not expanded, so the concept "animal" is not check, and the values of "eye of animal" are not added) |
| - how many necks | does the person have? | 1 | → from the parent "mammal" |
| - how many fur | does the person have? | Any | → explicit value |
INTERACTIONS
Using the kind of question described here and here, you can ask about the relations between concepts.
The searches made to answer this kind of questions are the same described for the frame/set search (taking in mind the deep search and filters).
In a brief words:
if exists and it has positive tendency then check if exists the asked receiver in the correspondent interaction list
in case of affirmative response to both conditions, then the answer will be "Yes" if the tendency of the interaction is positive, "No" if the tendency is negative (on the contrary in case of negative question).
Let's see some examples using the following example data set:
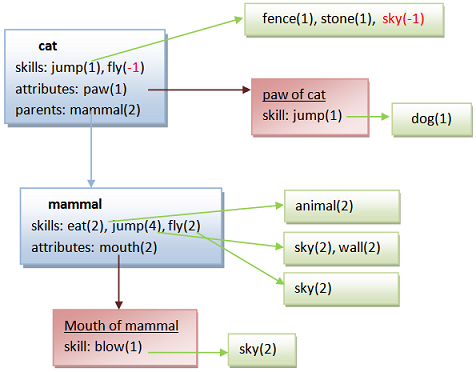
| * deep search off | |||
| * all filters off | |||
| - can cats | jump a fence? | Yes | → positive interaction tendency |
| - can cats | jump sky? | No | → negative interaction tendency |
| - can cats | jump the forest? | No | → no interaction found |
| - can cats | run a forest? | No | → no skill found |
| - can cats | fly sky? | No | → negative skill |
| - can cats | jump dog? | Yes | → by attribute inheritance |
| - can cats | eat animals? | No | → no skill found |
| * deep search on | |||
| - can cats | eat animals? | Yes | → by parent inheritance |
| - can cats | fly sky? | No | → by parent inheritance yes, but this skill relation is explicitly negative in the frame of cat |
| - can cats | blow sky? | Yes | → by attribute inheritance of the parent inheritance |
| - what does cat eat? | animal → by mammal |
| - what does cat run? | None → no frame has the relation |
| - what can jump wall? | mammal, cat → cat is for the parent inheritance |
| * tendency filter = 2 | |
| - what does cat jump? | sky, wall → by mammal; the jump relation has 1 as tendency so it's filtered |
| * tendency filter = 3 | |
| - what can jump wall? | mammal → the parent relation has 2 as tendency so it's filtered |
| * tendency filter off | |
| * multiple source filter on | |
| - what does cat jump? | None → all the relations has been created with only 1 source; so any active source filter will purge any relation |
FILTERS
As the system is feed through English sentences, it may occur that processing a lot of them, some could be misinterpreted or not having enough different mentions to be considered valid.
E.g.: "the blue cat" it's mentioned 3 times in only one text, but "the black cat" thousand of times and "the white cat" by 6 different sources.
So if you ask about what color is a cat, the system will answer blue, black, and white.
For this reason, it has been created a mechanism to indicate some search criteria to discard those weak relations without remove them from the memory.
Then all the searches can be tuned for discarding those relations that are not quite strong to be considered true.
Let's see some examples using the following example data set: