
Implicated source code:
File Language.h/.cpp
Class Language (main)
Class ILcode (internal language code)
File NLPparsing.h/.cpp: Stanford NLP core management
Class NLPparser (manager)
Class Token (words / part of the speech)
Class Dependency (dependiencies / relations)
Sentence analysis
This function process the user input (text with declarative sentences) and generates a response (memory learning)Source code = Language::process()Lexical Level- Language:: Lexical() Sintax Level- NLPparsing::process_sentence() + [ NLPparsing::NLPstanford(), NLPparsing::Dump_xml_data() ] - NLPparsing ::getSintax() + Class NLPparsing::Token - Memory::Manage_Word() Grammar Level- NLPparsing::grammarAnalysis() o NLPparsing::extract_sentence() o NLPparsing::parseNPP() + [NLPparsing::transformNP(), NLPparsing::transformPP(), NLPparsing::transformREL() ] o NLPparsing::parseVL() o NLPparsing::parseOP() + [NLPparsing:: parseNPP(), NLPparsing::parseADJV() ] o NLPparsing::extractNP() - NLPparsing::getIntermediateLanguage() + [Language::Transform2Internal(), Language::preprocessILcodes() ] Semantic Level- Language::Semantical() [ with tendency == 0 that means LEARNING (insert into the memory) ] |
Lexical Level
| |
|
This sub-process receives a text input from the keyboard or a file, then cleans and transforms every character to a expected values for the next sub-processes, and then split the text into sentences that is given one to one to the syntax and grammatical analyzer.Source code = Language::Lexical() |
Sintax/Grammar Level
 |
 |
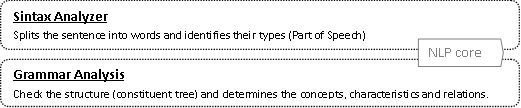
This phase receives a simple sentence in text format, calls the Stanford NLP Core, get the results of the analysis, with that results get the POS (concepts) and apply some rules to the constituent tree to extract their relations (in intermediate language format). At this point this information is already prepared to be processed by the semantic analyzer.Source code = NLPparser:: process_sentence() |
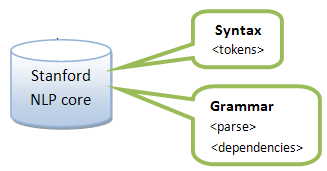
Stanford Core NLP receives a sentence and returns an XML file with the sentence syntactic and grammatical sentence analyzed:
...
<tokens>
<token id="1">
<word>the</word>
<lemma>the</lemma>
<CharacterOffsetBegin>0</CharacterOffsetBegin>
<CharacterOffsetEnd>3</CharacterOffsetEnd>
<POS>DT</POS>
<NER>O</NER>
<Speaker>PER0</Speaker>
</token>
<token id="2">
...
<tokens>
<parse>
(ROOT (S (NP (NP (DT the) ...
</parse>
<dependencies type="basic-dependencies">
...
<dep type="amod">
<governor idx="3">cat</governor>
<dependent idx="2">nice</dependent>
</dep>
Stanford NLP core uses the Penn Treebank tags for catalogue the part-of-speech. You can find here the list of tags described in Penn Tree Bank.
And you can find general information about deal with grammatical trees.
Also, a complete example of .xml results file obtained from Stanford NLP core.
There is a token for each word in the sentences with some syntactical useful information about the words. The relevant are:
<word> his value will be inserted in the dictionary referencing their correspondent entry in the lexicon (his lemma)
<lemma> canonical form of the word; as in semantic memory the form of the word is not important, the lemma is a good reference to englose all the forms of the word to their meaning; → it will be inserted in the lexicon plus their type (POS)
<POS> Part Of the Speech; the type of the word in this sentence; CoreNLP uses Penn TreeBank tags, if the POS is JJx(Adejective), VBx(Verb), NNx(Noun) then this word will be stored in the memory. Also RB (Adverb) although does not have semantic meaning it will be store for future purposes, and CD (cardinal) but using his value from the tag NormalizedNER and PRP (personal pronoun) but in this case will be translate as if has a designed "person" as NER.
<NER> (named entity relation): if is different than 0 and is a "location", "person" or "organization" the lemma will be replaced for this value. Remember in semantic memory there aren't proper nouns or instances, only conceptualization. Note: all that concepts are pre-defined in the memory both in the dictionary as in the frame system.
Also provides the grammatical analysis in a constituent tree format (<parse>)
as well as in Dependencies format: <dep type="amod"><governor idx="3">cat</governor><dependent idx="2">nice</dependent></dep> → "cat" has an adjectival modifier (amod) "nice"
Dependencies are large and complex, but if you would like to deep into: dependencies.
With that very useful information the system can apply some rules to extract features of the implicated objects.
Reference point of the grammar analysis model:
1. Found the concepts, that are the main nouns identified into the NounPhrases.
NLPparsing::parseNPP() + NLPparsing::parseOP()
2. Associate the identified characteristics with the concepts; characteristics are the semantic words that are preceding the main noun in a noun phrase.
NLPparsing::transformNP() + NLPparsing::extractNP()
3. Getting the main verb (VP) and the subjects (NP) and objects (NPs in VP), identifying properties and relations.
NLPparsing::extract_sentence() + NLPparsing::parseNPP() + NLPparsing::parseVL() + NLPparsing::parseOP()
4. Whilst, if in the subjects of the NP part has Prepositions Phrases (PP) then also extract characteristics from them.
NLPparsing::transformPP()
5. Finally, the process also manages relatives clauses or "WH" (which, who, that) subphrases.
NLPparsing::transformREL()
Semantic Level
 |
 |
Due to the objective is learn semantic knowledge from the sentences, this process receives the results of the prior processing, the extracted syntax and the grammatical relations in a intermediate language format and it converts into internal language, which is the format that learning process can manage to finally store into the memory.Source code = Language::semantical(ILcode) |
Semantic phase is a stage where the sentence gets meaning, when it's understood what the message brings. The system understand that at this point there are some concepts and characteristics and relations extracted from the prior phases, and have to store into the memory (learning).


Question Answering

Questions are received in the interface

Implicated files: main.cpp and cmd_interface.h/.cpp
Source code:
Language::question()
Language::Semantical() // ILcode with tendency == 0 means question; if extra == 'what' also means group type question
Affirmative questions
Language::Question_Affirmative_Graph()
Group questions
Language::Question_Group_Graph()
Numbered attribute questions
Language::Question_Numbered_Graph()
Confirmation
cmd_interface::Qconfirmation()