
This model without data is incomplete.
So, It's needed some mechanisms (Information extraction) to obtain sentences that would be processed to get relations that populate the system.
After processing +256K wikipedia articles and +27K random webpages, which provided about 4,5M sentences.
There has been identified +2M semantic words, 900K concepts with about 6M relations.
You can download (here [65MB zip / 310MB]) the "memory.txt" file.
Query online a dataset of relations.
For alternative purposes you can download the extracted words:
adjs.txt: with 89759 lemmas and 163418 related terms
verbs.txt: with 17737 of lemmas and 62631 related terms
nouns.txt: with 906949 of lemmas and 1757538 related terms (only common nouns) [12MB zip / 36MB]
These files has the following format: lemma1:term1{,term2,...}/lemma2:term1{,term2,...}/...
Note: into the term list it appears at least the lemma. E.g.: cat:cat,Cat,Cats,cats/boy:boy
In the following are presented some tools for provide sentences and achieve a considerable amount of useful knowledge.
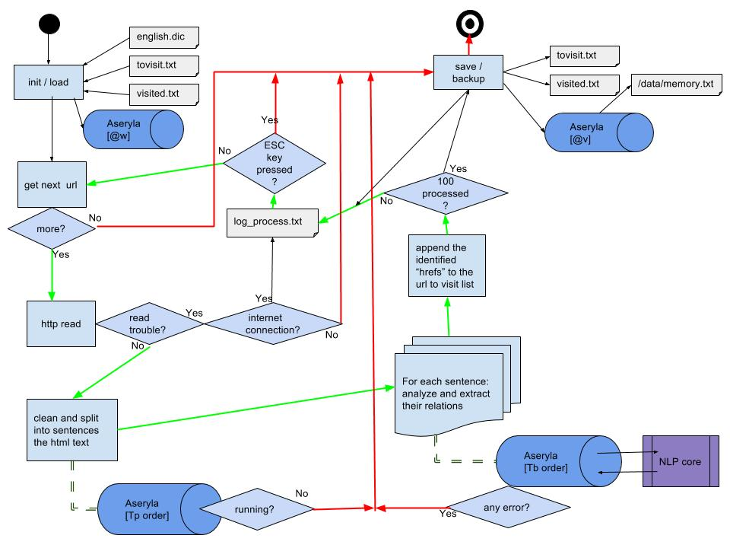
Crawling the web
1. Assuming you have correctly installed version 2.7 of Python, an functional internet connection and both aseryla and NLP services are properly running.
2. From a console (very important) run the "WebExtractor.py" python script.
3. You can also check the progressed webpages using the "STATS.py" script,
that condenses the content of the "webextractor.log" output file and the "memory.txt".
Download the scripts here.
Retrieving text in a web page has some collateral effects (usually due to in the web page the words are separated by sections or columns in a table);
Usually the process identifies large group of words as person or organization, producing concepts that are specializations with more than 3 words, as "mike_johnston_paul_bean_mike_turner".
So, in the package you also can find the python script "clean_relations.py" for cleaning the extracted data.
Also remind the memory purging (easy of use from the GUI).
Some stats after analyze 1 Million sentences
(Here one with 15 duplicated words!! "beeswax, beeswax leather, black, black suede, bronze or brown suede, brown suede, burgundy leather, evergreen suede, fudge suede, green leather, green suede, grey suede, loden green leather, maple, maverick leather are the literals")
most in the OBJECT part, a few with multiple elements, only 2 cases identified as "made of") (E.g.: "Mike explained the challenges of singing and dancing")
E.g.: "actress, who will be presenting tonight, hit the red carpet in a blinding and super cool black and white checkered dress"
Parsing the wikipedia
1. Having correctly installed version 2.7 of Python.
2. Download the latest dump of English articles of the wikipedia:
3. Use the MediaLab wikipedia extractor script to remove all the wiki-tags.
This process spends +3 hours for a complete extraction of 8,6 million articles.
4. Merge the output files in only one xml file
That will contain a "doc" tag list with the articles in plain text, such as:
<doc id="5776559" url="https://en.wikipedia.org/wiki?curid=5776559" title="Pegloteman">
Pegloteman
A fictional persona.
</doc>
<doc id="50776299" url="https://en.wikipedia.org/wiki?curid=50776299" title="File:Nancy Broadway With Love.jpeg">
File:Nancy Broadway With Love.jpeg
</doc>
<doc id="50776095" url="https://en.wikipedia.org/wiki?curid=50776095" title="Is Theosophy a Religion?"←
Is Theosophy a Religion?
Is Theosophy a Religion? is an editorial published in November 1888 in the theosophical magazine Lucifer; it was compiled by Helena Blavatsky.
It was included in the 10th volume of the author Collected Writings.
The article begins with the statement (the author has reproduced it repeatedly elsewhere) that there is a general sense of confusion.
Year after year, and day after day had our officers and members to interrupt people speaking of the theosophical movement.
Still worse, it is as often spoken of as a new sect!
</doc>
. . .
5. Run the "WikiFilter" python script to remove any non ASCII value and prepare the file content to be processed.
6. With both aseryla and NLP services are properly running.
7. From a console (very important) run the "WikiProcess" python script.
You can stop the process pressing the ESC key, and continue by the last processed article the next time you run the script.
You can stop the process pressing the ESC key, and continue by the last processed article the next time you run the script.
Take in mind that processing the entire file may need several months of continous running.
8. For checking the progress, you can run the "stats" python script that condenses the content of the "wikiprocess.log" output file.
Get all the necessary scripts here
Alternative resources
Remind that this pages has copyright and the extracted data can't be used for commercial purposes.
Direct input
Providing text files directly through the interface.