
Model: Considerations and Limitations
List of some considerations and limitations about the current model, some of these points are in progress to be included in future versions.
Memory
At this version the model will have the ability to store all kinds of general concepts
(non-specific or instances) together with their different characteristics.
Even direct interactions between them; Despite those tasks involve other brain processes such as
logic, episodic memory, deduction, etc. that are outside of the scope of this project.
Learning
The system has also the ability of learning in a unsupervised way,
though it offers the possibility of human intervention for correction
and validation of the information that has been processed.
One of the main capabilities is to be able to learn all kinds of concepts and auto-correct
them based on a statistical model applied over the global inputs received.
Language
The application is designed to work only with English, especially for the ease of having a grammatical parser that works quite well
(Stanford NLP core).
However, the model is designed for support any other language; simply it's necessary to adapt the
analysis of the sentence part,
because the insertion and search memory structures
(and the internal language) are already adapted.
Another functionality that could be very interesting is using this system to help in some
machine translation tasks.
Creating the conversion between the words in the dictionary/lexicon, the knowledge stored in the frames/sets will be remained.
Logic
The concepts (frames) can describe abilities (skills), but not their implications, as if it has wings can fly.
That task implies logic, deduction and other mental processes that are not covered with the semantic memory.
Nonetheless one of the objectives of this project is to provide a system to allow reach tasks like that.
The model provide mechanisms to store that mouse can eat, and mice can be eaten, but not that cats eat mice;
Note that cows also can be eaten, then can cats eat cows?.
Instantiation
The current model only allow storing knowledge about general concepts, not to specific objects
as John Smith is from England and weighs 80 kg; from a sentence like this, the system extracts relations as persons has weight and location.
In future versions, it will add this functionality to the model.
Consciousness management
Currently the application does not have any status or mechanism to apply "maintenance" tasks (during the sleep phase), such as:
- sorting the data lists by frequency to do queries (answering questions) more efficiently (memory arrange)
- memory purge
- consolidation of the knowledge: confirm the assertion with third party systems
- learning new knowledge, for example, searching in the web
- . . .
Synonyms
The system does not provided a specific mechanism to represent concepts that are equivalent, as human = person.
But the model allows multiple inheritance, it can be indicated into the memory with a double parent frame relation.
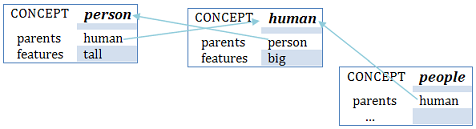
Using this "trick", you can implement that characteristic in the memory model. Thus allows sharing the characteristics of various equivalent concepts.
In this scenario asking if people is big or/and large will be responded as Yes in both cases due to the inheritance properties.
In fact, people could has person instead of human as parent and it will obtain the same results; even having both without any difference.
Gradations
The model allows specifying characteristics to concepts, but no gradation over them.
As for example "cats run faster": cats can run, but not how fast or slow it does. Or my car is red: but not which intensity of red.
The system is capable for catch the adverb references. But this characteristc is currently disabled in the system.
Properties over the characteristics
You can specify quantities to the attributes of a concept (numbered attributes).
Such as A cat has four legs or cats weigh between 4 and 5 kg
Due to Stanford NLP core provides that information:
Hair is between 1 and 10 centimeters
(NP ...(QP (IN between) (CD 1) (and) (CD 10) (NN cen ...))
Normalized NER [1.0-10.0] [1.0-10.0]
On the other hand, It's quite important the structure of the sentence, depending of the constituent tree returned by Stanford NLP core, the language processor can lose the numbered attribute.
The four legged cats (ROOT (NP (NP (DT The) (CD four [NER =4.0])) (NP (JJ legged) (NNS cats))))
As the number is outside the NP branch, the language processing does not assign the number to the attribute.
However, it process correctly sentences as the four legs of cats (NP (NP (DT the) (CD four) (NNS legs)) (PP (IN of) (NP (NNS cats)))))
Polysemy
The model does not implement mechanisms to distinguish when the same word represents different concepts,
as mouse that could be an animal and a computer device.
The system will store all the characteristics in the same frame,
and therefore a mouse could be electronic and live, or metallic and having fur at the same time.
Though that is true, is needed a disambiguation method.
On the other hand, a characteristic could be Yes and No at the same time. For example, the following case:
| - communication is verbal(talk) | → communication is verbal +1 |
| - communication was not verbal (gesture) | → communication is verbal -1 |
In this case, the tendency of the feature verbal of the frame communication will set as zero (Unknown). This could be solved using different labels, as verbal and non-verbal.
Comparison
For the system every characteristic has the same value or gradation, then if a tiger is big and an elephant is big
with this model tiger and elephant has the same "size".
Conditionals
In term of semantics, conditionals are discarded, because requires comparison between the concepts, such as logic or deduction ..., processes that are not covered by the system.
However, from conditional sentences could be deduce some characteristics. E.g. Cats run faster than turtles: if cats run faster than turtles, this implies that turtles also can run.
Watch out: Stanford NLP core sets "incorrectly" the lemma when deals with conditionals; (JJR faster): lemma = faster (instead of fast) [see the about the lemmatization point ].
Multi-word term/concept (specializations)
The system was design based on the idea of one word, one concept.
But some concepts are represented using more than one word, as "hard disk", "football team".
Currently there is not implemented a mechanism to capture this need, except the ambiguous adjectival noun or choosing the adequate characteristic;
E.g. for the concept "dark blue":
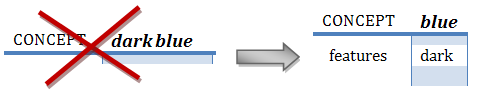
Anyway this represent several problems as inconsistent references as for example in the sentence
a basket team has 5 players the attribute "5 players" is referring to a "team of basketball" not to a "team" in general.
However this is also a problem of interaction and instantiation.

Other problem is in the subject movement of characteristic assignment when ISA assertions 
The sentence "a coupon(noun) is a discount(noun) ticket(noun)" will produce the following internal language codes: coupon ISA ticket / coupon ADJNOUN discount.
When really it should be produce something like: coupon ISA ticket_discount.

The model added a mechanism (called specialization) to manage the multiple concept representation (with also the aim of removing the "Ambigous Adjectival Noun" frame slot )
When the system finds consecutive nouns it interprets as only one concept.
"a great(J) football(N) team(N)" → concept: football team / football_team IS great
* multiple words concepts are internally represented with _ separator, this the way of mantain the "one word, one concept" model assumption
- it assumes that each specialization has a parent relation with its last noun → a football team is a team
- on the other hand, the rest nouns are not interpreted as associations (football team is a football), because is out of the scope of the semantic model
(it's a relation between concepts) → "a team that play football"
- if any of the words that composing the specialization it has a type of word different than noun, then their corresponding relations are created (IS for the adjectives, CAN for the verbs)
the Red(J/N) Brave(J/V/N) Siuox(N) → red_brave_sioux ISA sioux / IS red (also is adjective) / IS brave (also is adjective) / CAN brave (also is verb)
Specializations also is applies for the objects and the attributes
"the company has good auto prototypes"
subject: company
object: auto_prototype
relations: company HAVE auto_prototype / company%auto_prototype ISA prototype / company%auto_prototype IS good / company HAVE prototypes*
* when an attribute is also a specialization then the main noun also is added as attribute
does the company has auto prototypes? yes
does the company has prototypes? yes
does the company has auto? unknown (only the main noun of the specializations is also added as attribute relation)
In case of the same word is repeated, the duplicates ones are removed.
"the New York newspapers are cheap" → [lemmatization] the location location newspaper be cheap → subject: location location newspaper ==> location_newspaper (not location_location_newspaper)
This model assumes that "New York newspaper" is the same concept than "Boston newspaper"
With the specializations mechanism, the sentence "the football team has 11 players", it will create the following scenario:
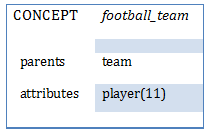
instead of the old model representation:
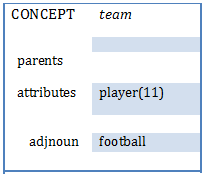
Of clauses
The model adds some assumptions to deal with this ambiguous scenario of managing sentence with of prepositions
(with also the aim of removing the "Of Clause" frame slot )
In essence, ofclauses are attribute relations, except if "made" is indicated in the sentence, then they are specializations.
The sentence: the wheels of truck are expensive
with the old model representation: wheel IS expensive / wheel OFCLAUSE truck
with the new model: truck HAVE wheel / truck%wheel IS expensive
The characteristics of the of clause does not belongs to the attribute association
E.g: the wheels of large trucks are big
large is associated to truck not to "wheels of truck"
big is associated with "wheels of truck" not to wheels
This rule does not apply when Proper Nouns are involved (those ones who have NER associations; locations, organizations and persons)
nuts of Brazil are sweets → nut IS sweet (not "location HAVE nut" relation is created)
There is an exception, when "made of" is present
tables made of wood are expensive → wood_table IS expensive (+ wood_table ISA table)
note: if made of is not present, then "table of wood is expensive" → wood have table
Lemmatization
This model is based on having a correct lemma to represent the concepts: different lemma implies different concept.
The task of lemmatization is left to the Stanford NLP core witch assigns the correct lemma to every word in almost all of the cases.
There is a problem when the word is not set with the correct lemma.
Taking this example, the system receives the following internal language codes:
- WORD N writing write
- WORD V writing writing
As is described here, in the lexicon the type will be updated, but never their lemma.
Note the system can't distinguish which one is the good one.
Inheritance choice
When a deep search is produced into the memory, the process stops when finds the first frame that it has the asked characteristic with positive tendency.
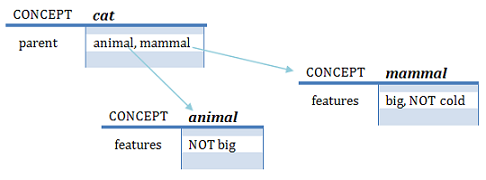
Assuming the scenario of the figure. The question is a cat big? will be response as Yes,
because big is found in mammal with positive tendency, even it was found before in
animal (remind the search is first in depth) but with negative tendency.
Conversely if the question is is a cat cold? then the answer will be response No,
due to at least one of the nodes explored has the characteristic with negative tendency, but none of them with positive tendency.
If the asked characteristic does not exist in any node, the response will be Unknown. In the last 2 scenarios the search explores all their related nodes.
In any case, this scenario could be disambiguated using the question confirmation or adding the characteristic directly into the affected frame.
In this case, for example, inputting the sentence cats are big or the cat is not big;
as the characteristic is found directly in the main frame, then their parents are not explored.
Skill inheritance of attributes
Due to its nature, the skills of the attributes are also assumed as if also belong to the parent frame;
the rest of characteristics belongs uniquely to the attribute.
For example:
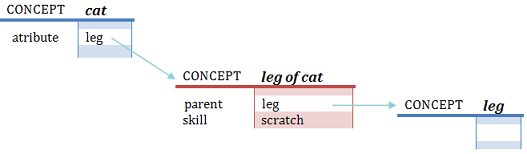
can cats scratch? Yes. Although scratch it does not exists directly in the skill list of the cat, but cat has an attribute (leg)
which skill list contains the searched characteristic (scratch), therefore this skill is assumed by the system
as own of the parent frame, so "the cat can scratch".
Remind, you can ask about the characteristic of an attribute using the "of" in the questions, so many times as levels you can ask.
For example, "does the legs of the cats have claws?" (1 level) or "are the claws of legs of cats retractile? " (2 levels)
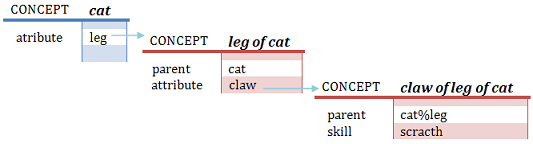
Added also inheritance choice behaviourin the searches.
When a skill is search, is also search in their attributes, and also in their parents and attributes of that attributes
Then "can claw of cat scratch?" the response will be Yes
This rule also is applied for attributes and affected actions ("does cats have claw?" Yes)
But not to the parents (a cat is not a claw), nor features (a cat is not white only if its legs have white color)
Also, with the mode confirmation set to on, if you ask is arm of cat nice? the application will response Unknown (as cat does not have arm as attribute) ,
and then it confirms with Yes, the system will run the internal language order "cat%arm IS nice 1" that is consistent with the petition.
The problem is that this order does not affect the memory, because the relation (IS nice) can't be created due to the frame cat%arm (relation cat HAVE arm) does not exist.
Obviously for this scenario the system should create this relation.
NER issues
Stanford Core NLP kit has defined some NER (name entity relations) over some words, as: John → Person; Paris → Location; Unesco → Organization.
As the system is focused in general concepts the system will set the NER as lemma at the syntax analysis.
Therefore John has legs will be interpreted as person has legs or The United States is a country as The location is a country.
To discriminate when a same word has different meanings, this rule only applies in case the first letter is in uppercase.
E.g. Fox increases the sales (Fox, the broadcasting company) against the fox run (fox in this sentence is an animal).
This rule can produce some troubles, as for example processing the sentence Missy(NER=person) is a cat that is interpreted as person is a cat.
Or the sentence New York is awesome is translate to location location is awesome (that produces: location IS awesome / location ADJNOUN location).
The model changed, and the lemma of the words with NER value is not replaced, the original lemma remains, but a parent relation with the NER value is created.
E.g.: "Mark(mark)[person]" is tall → WORD N Mark mark / mark is person / mark is tall. Instead of: WORD N Mark person / person is tall
This new design allows discriminating between different proper concepts.
Personal Pronouns
As personal preposition (I, you, ...) represents people, when is found in the sentence then is replaced by "person".
This behavior fits perfectly with the model. Nonetheless, "it" is not a personal pronoun therefore it can' be interpreted as "person" concept.
The possessive pronouns (mine, your,...) are discarded because represents "belonging" not description of the concepts:
Your car is green → car IS green, not person%car IS green
Specifically "the car of this person" is green, but this is an instantiation,
and is outside of the scope of the project, which is interested in the characteristics of the general concepts, not in the context of the sentence.
The impersonal and possessive pronouns are directly discarded in the lexical phase.
Tendency
Besides to know if a relation is positive or negative, this number also represents how many times the relation had been mentioned,
then maybe its representative of the percentage represented within the set. As example, after analyze some sentences, the system extract that
cats are blacks 13 times, meanwhile the relation cat is white has 2 mentions, by other hand cats are not pink is also mentioned.
Then the frame cat has a feature list as: black(13), white (2), pink (-1). This kind of information could be useful to deduce that most of the cats are black (86%).
Due to the tendency is unique for every assertion; the model can 't store both affirmations and negations over the same characteristic,
as for example a person could have hair or not; nevertheless could store a person could have hair or be bald. (see above the Polysemy)
Negations
Usually the language analyzer sets the tendency of the assertion based in the existence or not
the conjunction "NOT" in the verb phrase node.
Sentences as person is nice, lions eat has positive tendency associations
Sentences as the robot is not nice, the fox hasn't been running are interpreted as negative tendency associations
But there are some exceptions:
- As the process is only interested in declarative information, negative actions usually represents actions in a concrete moment or in the context, not general information about the objects, therefore the analyzer only consider as negative action verb if have the modal verb "can".
- I do not run today → assumes persons can run but this person in for any reason at this moment is not running (person CAN run +1).
- stones can't run in the garden → stones can't run is right, but it does not means that anything can't run in a garden. (stone CAN run -1 / garden CANBE run +1).
In the last example is remarked that indirect actions never are assumed in negative. This rule bring a problem when you would like to express them specifically.
For example to say that the sea is not overflown, processing the sentence sea can't be flight does not generate the internal language code "sea CAN flight -1".
Currently the only way of set this knowledge into the memory is to correct it using the manual confirmation mechanism.
- In negatives sentences with attributes, the analyzer assumes the negative is for the modifiers, not for the attribute.
chairs does not have little legs, the chairs has legs, but that legs are not little (chair HAVE leg +1 / chair%leg IS little -1)
- Also fot the case of "without" (with + not) prepositions sentences:
a man without hands → in this case the man is an instance; this man in concrete doesn't have hands, but men in general have hands.
a man without big hands → the man have hands but NOT big hands (man HAVE hand +1 / man%hand IS big -1)
Watch out: lions without mane are female this association can't be fit by the system due to implies logic(see the point above).
Nonetheless it can store the fact of lions could be female and can has mane.
- The negation is expanded to every object found;
In the sentence chairs does not have hands or lights, the language analyzer generates the following internal language relations:
chair have hand -1 / chair have light -1 !! (even the "not" is not referring directly to this object)
But the analyzer is not prepared to change the negation of the link verb between features.
Therefore in the sentence a chair has legs, backrest, not hands or head, the analyzer generates positive tendency relations for the four objects,
due to the link verb has is not accompanied by not, though the not associated to hands and even head.
Memory purge
The memory structures dictionary and frame stores
the number of times are referenced. This number plus the tendency and the source could be useful to identify what words, concepts and assertions
maybe was introduced in the system by an syntax error or are mentioned so little that do not deserve to be remembered.
For example, after being processed a large volume of sentences of several sources, in the dictionary every word has
been mentioned more than 1000 times, except 3,
it's likely those words are erroneous or not sufficiently contrasted entries.
Other possibility is removing those associations with a tendency number too lower or with not enough variety of sources (information not contrasted).
Currently it's not implemented any forgetting mechanism or knowledge purge (except the memory arrange).
Relative clauses
The analyzer deals correctly with relative clauses (that, which, who....),
but only for the record, those sentences are processed as subphrases what WH tags are being replaced by the subjects.
As for example, if you input the sentence cats and dogs, that are not robots, are mammals,
the system it will split and process as if you inputted the following sentences:
cats and dogs are mammals, cats are not robots and dogs are not robots
Correcting statements
The application allow the possibility of correcting manually (supervised learning)
the knowledge through the confirmation mechanism.
As for example, if the fact cat is mammal has been processed 10 times, then the system will answer Yes when is questioned about it.
If the confirmation mode is active, the system will reinforce
(adding the current trust to the tendency of that association) or correct (subtracting).
But the user, only asking questions does not receives information about the frequency, about only the tendency
("Yes" if positive, "No" if negative, "Unknown" otherwise).
- if the confirmation was answered with Yes then the relation is reinforced in frequency,
adding the current trust to the tendency of the relation.
E.g.: having the parameter trust set to 2 and the following relations:

| Question |
Confirmation |
New relation |
| is cat nice? Yes |
right? y |
cat IS nice 7 |
| do cats have wings? No |
right? y |
cat HAVE wings -4 |
- if the confirmation is No then the relation is corrected using
the correspondent policy based on the type of confirmation.
E.g.: continuing with the same scenario as above:
| Question |
Confirmation |
TENDENCY/MODE |
force |
invert |
detract |
| is cat nice? Yes |
right? n |
current=7 |
-2 |
-7 |
5 |
| do cats have wings? No |
right? n |
current=-4 |
2 |
4 |
-2 |
If the relation does not exist then is created (adds a new relation).
| Question |
Confirmation |
New relation |
| can cat jump? Unknown |
right? y |
cat CAN jump 2 |
|
right? n |
cat CAN jump -2 |
IMPORTANT NOTE: if the answer is Yes or No due to an inheritance property in a Deep Search
the new relation is created in the subject, it won't modify the parent relation.
E.g.: having the following scenario:
is cat nice? No (by inheritance) right? y
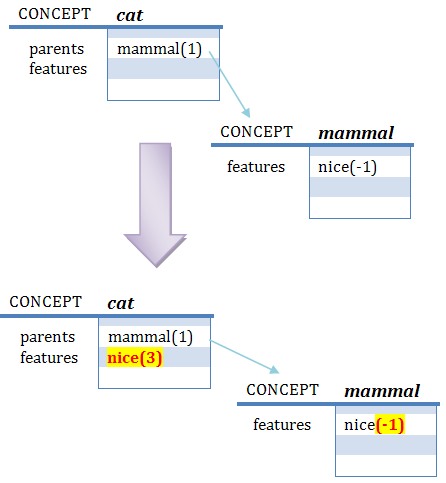
The parameter trust was set to 3 and Deep Search set to On.
As you can see the relation "mammal IS nice" will left untouched.
BE + preposition exception
When the language analyzer found a "verb BE following of an IN preposition" assumes the verb BE is indicating a location not an characteristic relation.
E.g.: Paris is in France: this means that the city of Paris is located in the country France, not that Paris has a feature or parent named France.
Every sentence that fits with the combination "BE + PP (IN ..." won't be interpreted as parent relation.
E.g.: cat is on the shelf (no relations extracted for cat and shelf), the pen is under the table or there are some bird above the fence
Complex sentences
Currently the language analyzer is focused in extract characteristic from simple declarative sentences (only one main verb or VP node).
But in the future could be enhanced to deal with more complex sentences, such as:
John begins to write his book
(S (NP (NNP John)) (VP (VBZ begins) (S (VP (TO to) (VP (VB write) (NP (PRP$ his) (NN book)))) ))))
a sentence inside of another sentence, or multiple verb phrase (VP) ; it could extract "person can write and also can begin"
Also, Multiple verbs: "He entered, greeted , saludated and waited for the coffee"
→ person can enter / person can greet / person can saludate / person can wait / coffee canbe wait
Even with negatives: "The angel did not come and can not flew out in the heaven"
→ angel can come (remind negatives only with can) / angel can fly -1 / heaven canbe fly
Modals and phrasal verbs: "I have to pick up the child" → person can pick
Dealing with auxiliaries: "He would have been sliced and diced" → person can slice / person can dice
Distransitive sentences as "She is baking him a cake " → person(she) can bake / cake can be bake (not person(him) can be bake)
(problem automatically solved removing the possessive pronouns )
Moreover, the analyzer cope correctly with modals, except with the composed as "have to/ought to" because the provided constituent tree brings a multiple sentence node
I have to write = (S (NP (PRP I)) (VP (VBP have) (S (VP (TO to) (VP (VB write))))))
The correct extraction must be person can write not person have write as currently is being processed.
And even sentences with the structure: ... neither/nor ... nor ...
As for example: stones neither eat nor drink → stone can eat -1 and stone can drink -1.
Memory backup
The application dumps the entire content of the knowledge loaded into the memory into the respective {aseryla}/data/memory.txt file
in internal language format.
The internal language codes extracted from the sentence analysis are also stored in database
Interactions
The model was designed to capture any knowledge about a concept, that is how the semantic memory store the information.
So, the model is capable for store what skills are applied to some concepts and what are affected, but not that relation.
E.g.: the mouse eat cheese → mouse CAN eat + cheese CANBE eat; but not the relation "mouse EAT cheese" because is out of the scope.
Anyway, this information is quite relevant, so the model has been extended to store those interactions.
Self Identity
The model assumes that each concept is the same concept itself, but not as characteristic.
So, "a cat is always a cat" but "cats never have cats" or "a jump can't perform the action jump"
Then if you input any ilc wich subject is the same as the object then the relation won't be stored into the memory. Anyway, if you ask for this scenario the system always response as " Yes" when the code is ISA/IS/ISAIS and " No" for the rest codes.